Source subscription job details
DM
The Job Details page for a source subscription displays the outcome, number of records imported or exported, and the number of bad records in the job. It also provides information so administrators and data managers can understand the settings that were selected for each source subscription job.
There are two tabs on the Job Details page:
-
Job Summary - Contains the status, settings, and records counts for the job.
-
Job Error Log - Contains error details to help troubleshoot job issues.
Note: If the job ran before the Job Error Log was redesigned in Veeva Network MDM 25R3.1 (February 2026), the Job Error Log displays as a section on the Job Details page.
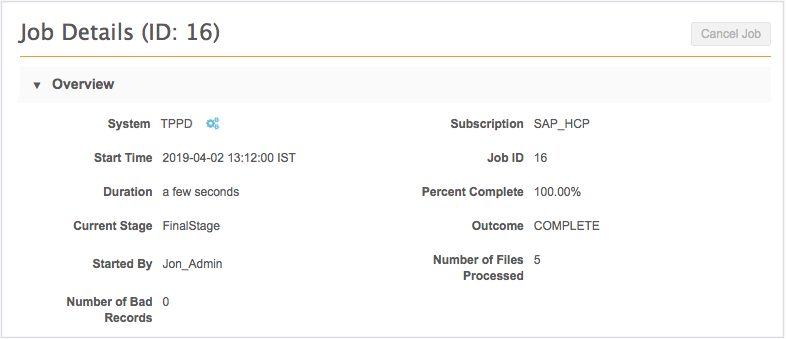
Overview
This section provides basic job status details about the subscription job.
Tip: A blue icon ![]() displays beside the System name so that you can quickly identify if the subscription used a third party source system.
displays beside the System name so that you can quickly identify if the subscription used a third party source system.
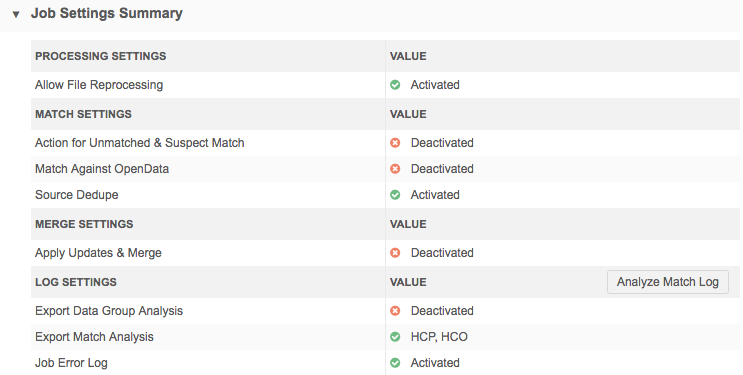
Job settings summary
This section includes the job settings at runtime.
- Identifies settings that were activated or deactivated for a particular job.
- Provides information about settings that were activated. For example, you can see the selected setting for Action for Unmatched & Suspect Match.
- Allows users to report against the match log for a source subscription job.
If Export Data Group Analysis or Export Match Analysis was activated for a subscription, an Analyze Match Log button displays. Clicking the button redirects you to the Advanced tab on the Ad Hoc Queries page where you can analyze the match log by reporting on it. For more information, see Match log report.
Note: It can take several minutes to prepare the match logs for reporting. You can navigate away from the Job Details page while the match log is being rerouted.
After you click the Analyze Match Log button, the button name changes to Match Log Published to indicate that the log has been published to reporting.
Match logs that have been created within the past three months are available for reporting on. After three months, the logs are purged and cannot be retrieved using the Analyze Match Log button.
Primary fields update summary
This summary identifies the updates that occur on primary fields during subscription jobs. Many customers use primary fields for business purposes like incentive compensation or territory alignment. When changes occur to primary fields, it can impact those processes, so this ensures that you are aware of the updates and you can make necessary changes.
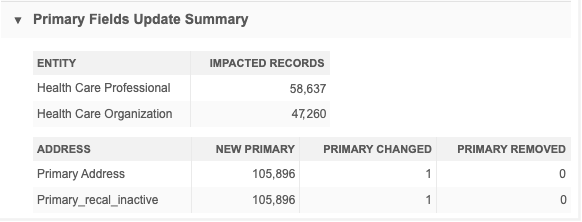
Primary field updates display for the Unique Checkbox primary type field only. The summary and counts do not reflect changes to the Network Calculated primary type field.
The summary does not display if your Network MDM instance does not have any primary fields defined.
Sub-objects and relationship objects
For each object, the enabled primary fields display and they are categorized so you can see how many primaries were added, changed, or removed during the job.
The following actions are tracked:
-
New Primary - A primary field was assigned to an entity.
-
Primary Changed - The primary was assigned to an entity but it was moved to another entity during this job.
-
Primary Removed - The primary was assigned to an entity but during this job it was removed and was not assigned to another entity.
Example 1 - New Primary
In this example, an existing record has one address where the primary field is set to NULL. A subscription loads five new addresses for the record that all have the primary set to true. Network MDM calculates the primary and sets one of the new addresses as primary. These updates count as one primary change.
| Existing in Network MDM | Update from subscription | Updates in Network MDM | Updates counted in summary |
|---|---|---|---|
| HCP A
address_a (primary=NULL) |
HCP A
address_1 (primary=T) address_2 (primary=T) address_3 (primary=T) address_4 (primary=T) address_5 (primary=T) |
HCP A
address_1 (primary=T) address_2 (primary=F) address_3 (primary=F) address_4 (primary=F) address_5 (primary=F) address_a (primary=NULL) |
New Primary = 1 |
Example 2 - Primary Changed
In this example, an existing record has an address already set to primary (primary = T (true)). A subscription loads five new addresses for the record that all have the primary set to true. Network MDM calculates the primary and sets one of the new addresses as primary. These updates count as one primary change.
| Existing in Network MDM | Update from subscription | Updates in Network MDM | Updates counted in summary |
|---|---|---|---|
| HCP B
address_a (primary=T) |
HCP B
address_1 (primary=T) address_2 (primary=T) address_3 (primary=T) address_4 (primary=T) address_5 (primary=T) |
HCP B
address_1 (primary=T) address_2 (primary=F) address_3 (primary=F) address_4 (primary=F) address_5 (primary=F) address_a (primary=F) |
Primary Change = 1 |
Example 3 - Primary Removed
In this example, an existing record has an address already set to primary (primary = T (true)). A subscription updates the existing address to change the primary value to False. This update counts as one removed primary.
| Existing record | Update from subscription | Updates in Network MDM | Updates counted in summary |
|---|---|---|---|
| HCP C
address_1 (primary=T) |
HCP C
address_1 (primary=F) |
HCP C
address_1 (primary=F) |
Removed Primary=1 |
Merge considerations
-
When entities are merged, if the primary address on the winning record did not change, it is not counted as a primary change. A primary change is only counted with the winning record's primary changes.
-
When addresses are merged on a record, a primary change is counted if the primary address is moved to another address.
Files loaded summary
This section displays the list of source files that were loaded and processed during the source subscription job. It can include information about the .zip file that was processed during the job.
The Folder / ZIP File field displays one of the following names:
- the .zip file that included the files that were processed
- the folder where the files were stored.
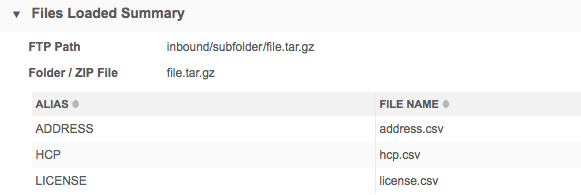
ZIP archive details
If the files that were processed were included in a .zip archive, you can view those details in the Folder/Zip File field. In the source subscription, the FTP Path field must be specified using one of the following formats:
- inbound/subfolder/*
- inbound/subfolder/<my_zip_file>
For example, if the FTP Path is inbound/dasource/*, then the Folder / ZIP File field displays the .zip file name.
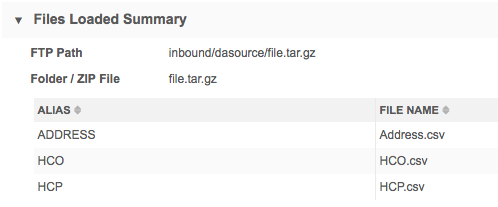
Folder details
The Folder / Zip File field displays the folder name in the following situations:
- If the files processed by a source subscription are included in a .zip archive but the FTP Path field is specified in one of the following formats:
- inbound/subfolder
- inbound/subfolder*
- The files that were processed were not included in a .zip archive.
In both of these situations, the Folder / ZIP File field, on the Job Details Summary page, displays the folder name.
Transformation queries
If transformation queries were applied to the subscription, the query output files are listed in this section but they are not added to the inbound FTP folder with the original source file. You can download the output files in the Transformation Queries section on the Job Details page.
Example
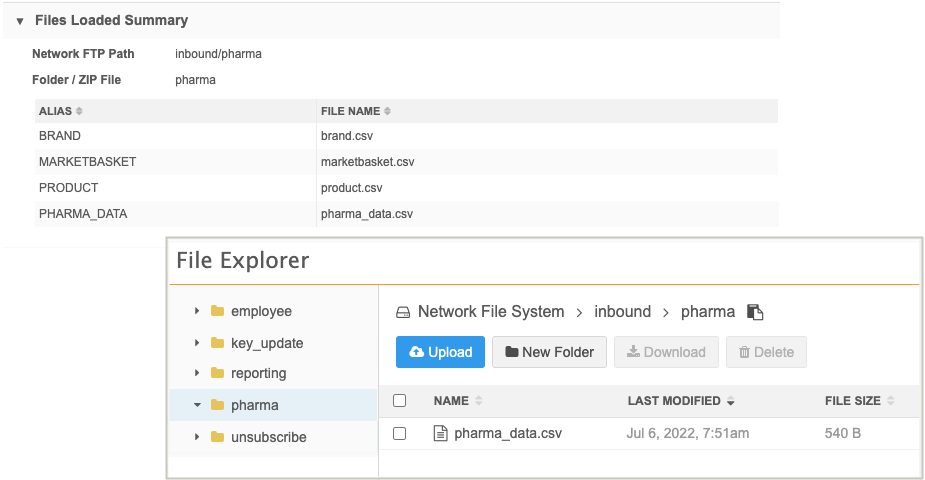
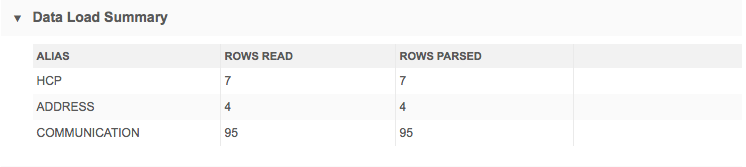
Data load summary
This section displays the count of source rows and source records that were loaded and parsed during the source subscription job.
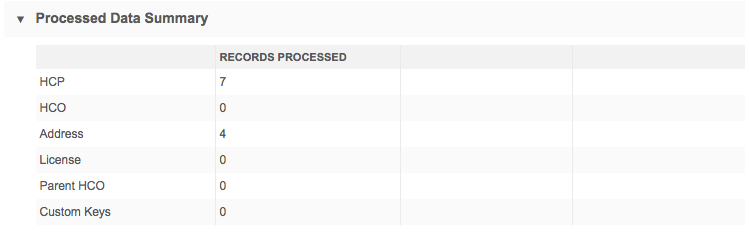
Processed data summary
This section displays the count of entities after the model stage of the source subscription job.
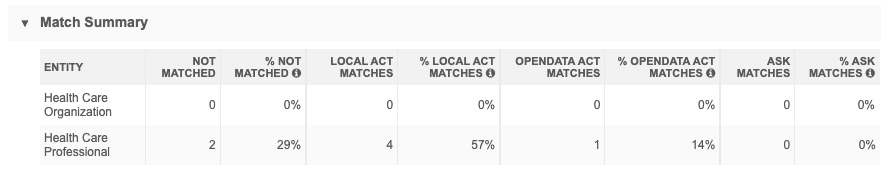
Match summary
The number and percent of records that were matched, the match type (either ACT![]() A high confidence match between two records. ACT matches result in a merge without any human review. or ASK
A high confidence match between two records. ACT matches result in a merge without any human review. or ASK![]() A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches), and how many did not match.
A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches), and how many did not match.
Note: The percentages may not equal 100% due to rounding.
Job result summary
Job results include details on the total number of each entity![]() A high-level record attribute; in general, an HCO or HCP. type loaded, added, updated, merged
A high-level record attribute; in general, an HCO or HCP. type loaded, added, updated, merged![]() The process of combining successfully matched records, or those manually identified as the same., invalidated, or rejected.
The process of combining successfully matched records, or those manually identified as the same., invalidated, or rejected.
The counts represent records during the merge stage of the job only.
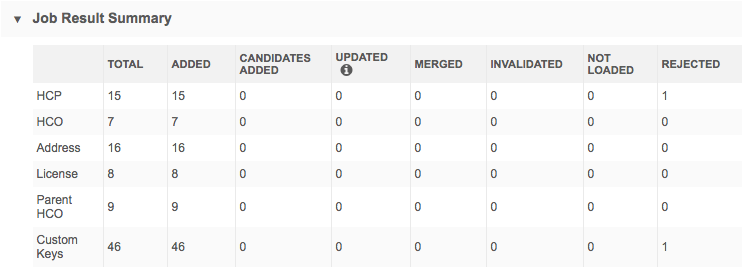
The Job Result Summary does not reflect issues or errors from other stages of the job; for example, Match stage and NetModelStage. The Job Error Log tab provides information about issues that occurred for all stages of the job.
Total records
The Total column includes the count of records added and updated (candidate records are excluded).
Note: In the Network MDM API, the total in the jobResultSummary response also includes records that were rejected and unchanged, so the total count between the Network MDM UI and the API appear different.
Not Loaded and Rejected records
To help make the data loading processes more transparent so that you can understand why your Network MDM database was not updated, there are separate columns for Rejected records and records that were Not Loaded.
Not loaded
This column contains the count of source records that were skipped or merged during the data load process.
Records are not loaded for the following reasons:
- Unmatched records are skipped - In the source subscription, the Action for Unmatched & Suspect Match option is set to No Action.
Rejected
This column contains the count of source records that were processed and loaded but were not persisted in the Network MDM database because there was an issue with the content of the record.
Records are rejected for the following reasons:
- Duplicate custom keys - Administrators have enabled the Reject Duplicate Keys option in the General Settings so that no duplicate custom keys can be loaded into their Network MDM instance. Records rejected for this reason are listed in the Job Error Log tab along with the duplicate key.
- ParentHCO records have invalid parent IDs - A ParentHCO record must have a valid parent ID and for the record (relationship) to be valid.
-
Parent HCO records have a related entity that is not Valid or Under_Review. This applies to candidate records and opted-out records also.
When Parent HCO records are not created for this reason, a message displays on the Job Error Log tab.
Example warning
A new PARENTHCO record was dropped from HCP <938061682273812525> due to related entity <938061682274730046> being not valid.
- Records have invalid reference codes. Records rejected for this reason are listed in the Job Error Log tab along with the problematic reference code.
- NEX rules - The Job Error Log tab displays the NEX rule that caused the record to be rejected during the After Update rule point stage of the data load.
Rejections are not tracked for the File Preparation and Transformation rule point stages. For more information about the rule points, see Using rule expressions.
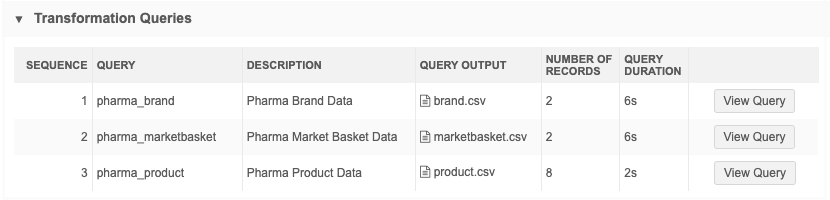
Transformation Queries
This section displays if one or more queries was applied to the job. If multiple transformation queries were applied, they display in the sequence that they ran.
Details
-
Query - The transformation query name.
-
Description - A description of the query.
-
Output File - The file created by the query. Click the file name to download it.
-
Number of Records - The number of records that were returned by the transformation query.
-
Query Duration - The runtime of the query during the job. For example, 2s means that the query runtime was 2 seconds.
-
View Query - Click to display a snapshot of the query that was applied when this job ran. It might be different than the query that is currently saved in Network MDM. Viewing the query as it was at run-time can help you to troubleshoot any issues that might have occurred.
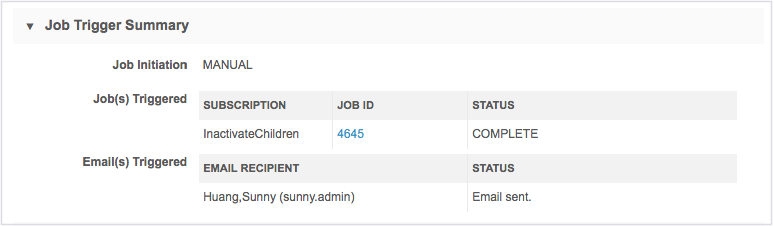
Job Trigger Summary
The Job Trigger Summary section identifies how this subscription job started. It could have been started from a job trigger on another subscription (for example, an OpenData subscription).
The Job Initiation value could be any of the following:
- Manual
- Scheduled
- Job ID - The job ID link displays if this job was triggered by the successful completion of another job.
If subsequent jobs or emails were triggered by this job, the details displays beside those headings.
Job Error Log
The tab displays if the job completed with errors or warnings or the job failed.
View reportable errors that occurred during all stages of the job. In your inbox, you can view job errors from data loads that are assigned to you or a group to which you belong.
Note: Error messages in the Job Error Log are only reflected in the Rejected column of the Job Result Summary if the error occurred during the merge stage of the job.
On the tab, hover over the Info![]() icon on the tab to display a count for each error severity to give you a quick summary of the issues.
icon on the tab to display a count for each error severity to give you a quick summary of the issues.
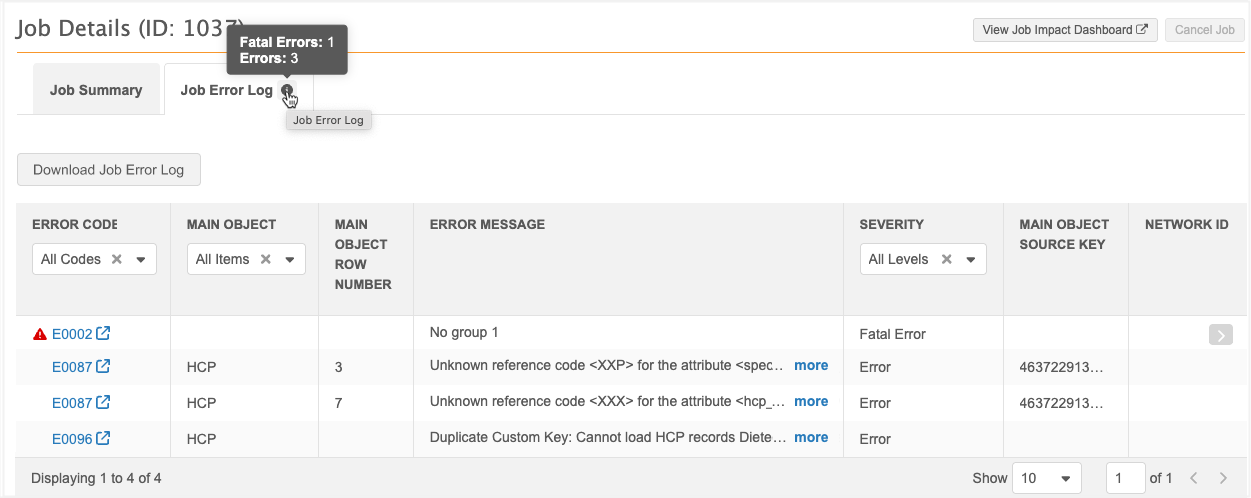
For detailed information, see Job error log.
Job Impact Dashboard
Click View Job Impact Dashboard to open the dashboard and see how the job has added or changed records in your Network MDM instance.
By default, the dashboard is filtered for the Job ID on the Job Details page.
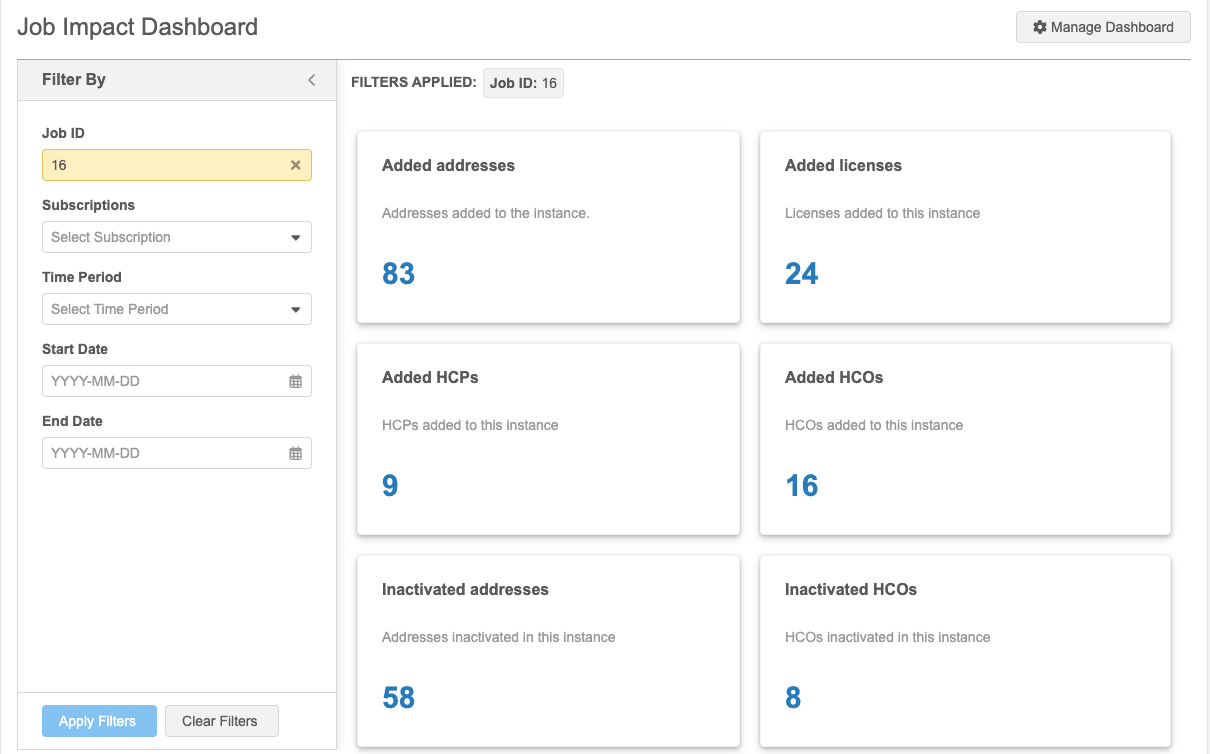
For more information, see Job Impact Dashboard.
Job summary reporting
For job summary reporting samples, see Job summary query samples.