Using rule expressions
DM
Use Network rule expressions (NEX rules) to enforce data quality standards when you process externally sourced data through source subscriptions. You configure rule expressions using a set of functions, operators, and statements to define specific rules for a particular stage of the data load.
NEX rules are also used in:
-
OpenData subscriptions (filter affiliations that are downloaded)
Formatting considerations
NEX rules must be created using specific formats in order to be valid.
-
Rule expressions defined in a source subscription must be enclosed in square braces ([ ... ]).
-
Data model field names are case-sensitive.
-
Field names that begin with a number; for example,
340B_id_1__v, must be enclosed in backticks (`).Example
[ "IF(`340B_id_1__v` == '5', SET(hco_status__v,'I'))" ]
Rule points
Rule expression configuration includes a number of rule points that define transformations or data feed acceptance criteria at various stages of the data load.
The data load stages include:
- File preparation
- Transformation
- After update
- Feed acceptance
Carefully consider which stage the NEX rule should be applied. For example, if you use a NEX function to cleanse strings, it should be applied in the File Preparation or Transformation stages before matching and merging occurs so you get better match results.
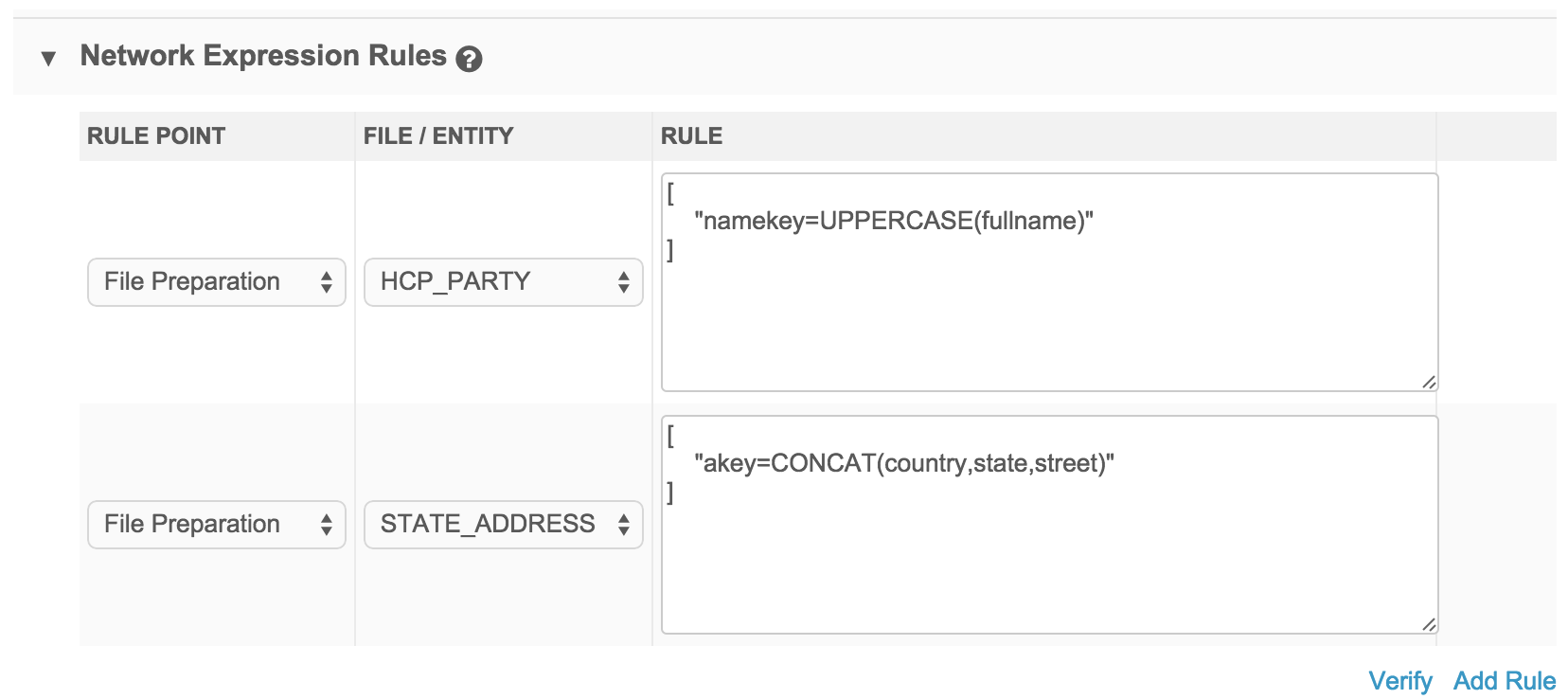
File preparation rules
File preparation rules are applied after Network MDM reviews each file individually, but before it joins them.
This rule point is often used to properly format custom keys.
If your subscription contains two files, they will ultimately be loaded into the same Network MDM object (for example, HCO) but will have different rules applied based on the file.
For this example, there are two files: HCP_PARTY and STATE_ADDRESS.
Transformation rules
Transformation rules are applied after Network MDM has modeled the files to the Network MDM data model, before matching and merging.
All functions are available for these rules except those that require traversal through a sub-object record. This includes the ANY and ALL functions.
Transformation rules can be used for cleaning strings by removing extra characters, or applying business rules specific to a particular subscription.
![]()
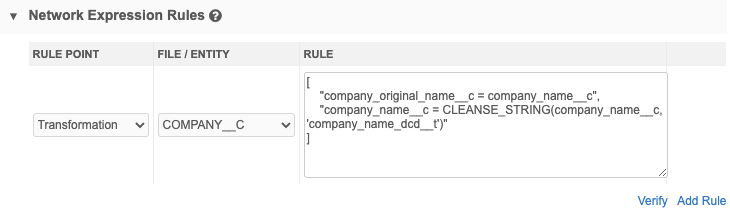
Cleansing strings
The Transformation rule point is the ideal stage to use NEX functions to cleanse strings. The rules are applied before matching and merging, so you will get better match results if you cleanse and standardize the values of the fields that you use in matching (for example, fields like hospital names, company names, product names, and so on).
The REGEXREPLACE function can be used (shown in the example above), but the CLEANSE_STRINGS function is a better option for effectively cleaning and standardizing strings. The CLEANSE_STRINGS function uses a data cleansing dictionary. For more information, see Data cleansing.
Example
In this NEX rule, original company name is moved into a new field and then the CLEANSE_STRING function cleanses the company name field.
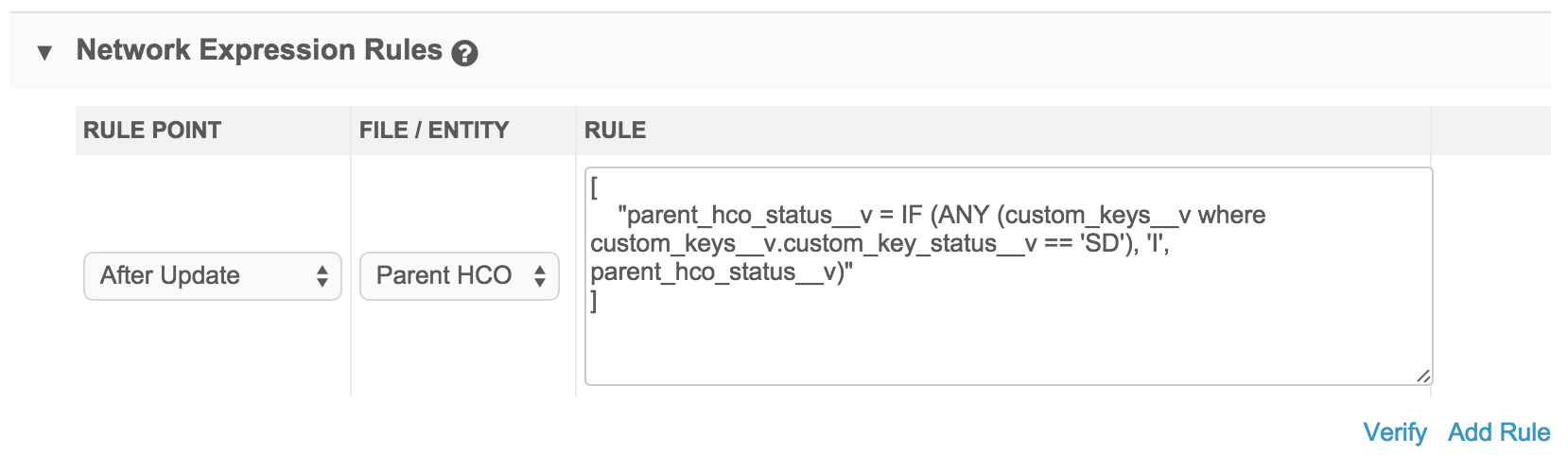
After update rules
After update rules are applied after Network MDM has joined files and matched and merged records.
All functions are available and are applied to the post-merge state of the data.
These rules only run on an entity for which data is being changed; If the import is identical to existing data, they will not run.
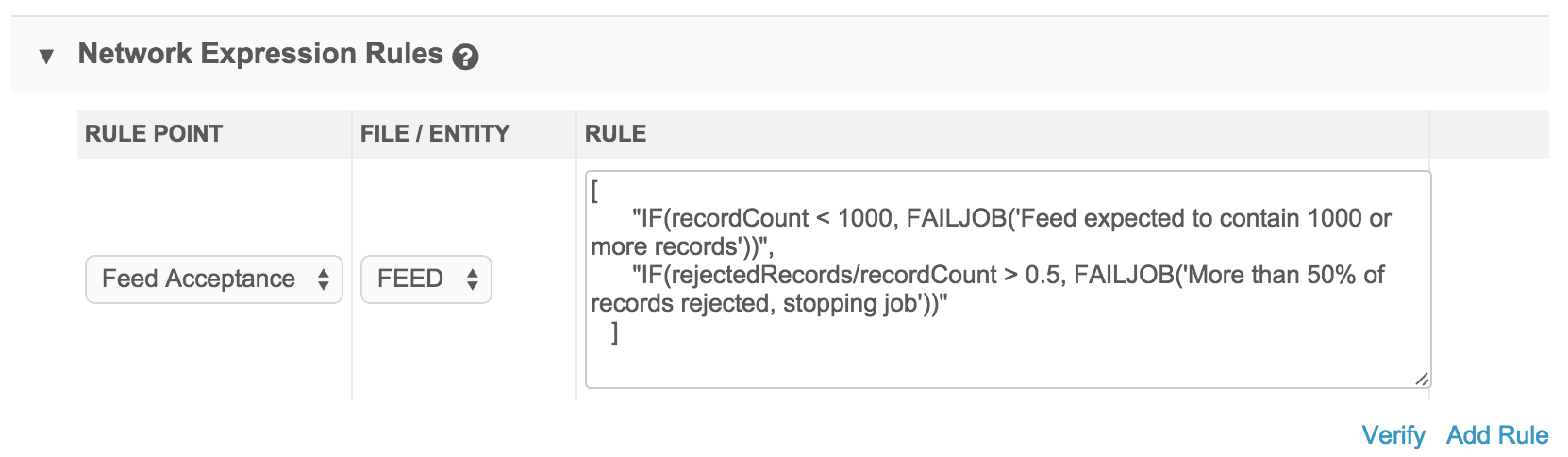
Feed acceptance rules
Feed acceptance rules are triggered at various stages of the load, based on the record count at each stage.
Configure rule expressions
To configure rule expressions, perform the following actions in the Network Expression Rules section of a source subscription:
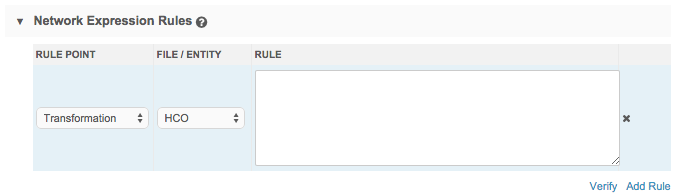
- Click the Add Rule link.
- Select the rule point from the Rule Point list.
- Select the entity for which the rule applies from the File/Entity list.
-
Type or paste your rule expression code in the Rule text area.
Tip: Use the NEX Tester feature to write, format, and test the expression. Copy and paste the tested expression in this configuration.
- Click the Verify link to verify your code.
- Click the Add Rule link to add more rule expressions.