Job summary query samples
Network MDM users with access to the SQL query editor can create reports to review job details and aggregate statistics for every type of job that has run in their Network MDM instance; for example, source and target subscriptions, and data maintenance jobs.
Job reporting schema
Job Details and Job Stats tables help users investigate the details of a job.
Use these tables to help build your SQL query.
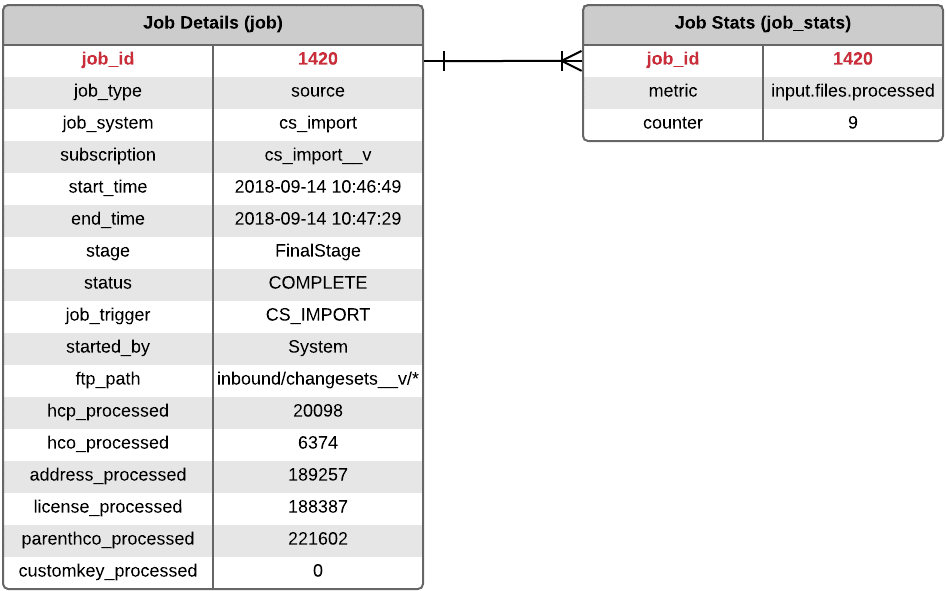
Job Details table
The Job Details table contains fields that display on the Job Details page.
Overview fields
| Field | Label | Description |
|---|---|---|
| job_id | Job ID | Unique identifier for the job. |
| job_type | Job Type | Subscription type for the job. |
| job_system | System | Data source for the job. |
| subscription | Subscription | Name of the subscription. |
| start_time | Start Time | Time that the scheduled job started running. |
| end_time | End Time | Time that the scheduled job stopped running. |
| stage | Current Stage | Current processing stage of the job. |
| status | Outcome | Outcome of the job. |
| job_trigger | Trigger | Schedule type of the job; either Manual or Scheduled. |
| started_by | Started By | Network MDM user that created the job. |
| ftp_path | FTP Path | FTP path where the subscription files are stored. |
| feed_name | Folder / ZIP File | Folder name and files that were processed for the job. |
The fields in this table map to the Overview section at the top of the Job Details page.
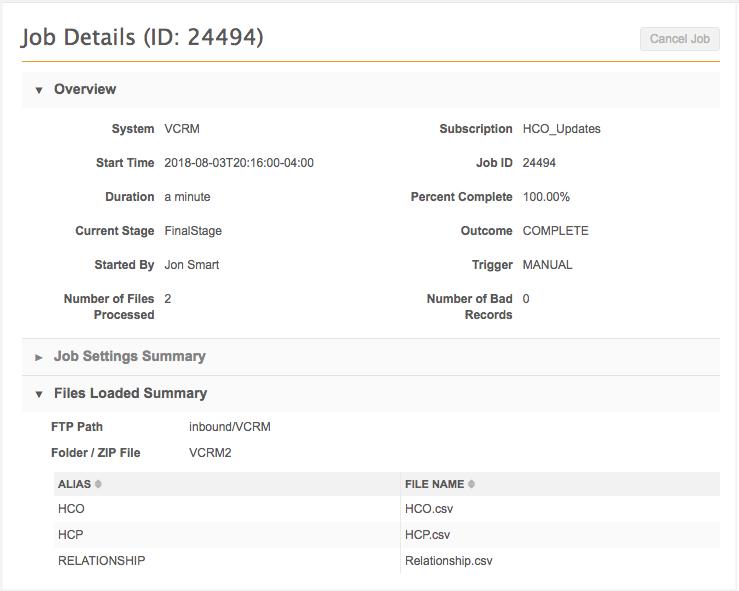
Processed Data Summary fields
| Field | Label | Description |
|---|---|---|
| hcp_processed | HCPs Processed | Number of health care professional records processed by the job. |
| hco_processed | HCOs Processed | Number of HCO records processed by the job. |
| address_processed | Addresses Processed | Number of addresses records processed by the job. |
| license_processed | Licenses Processed | Number of licenses records processed by the job. |
| parenthco_processed | Relationships Processed | Number of relationship records processed by the job. |
| customkey_processed | Custom Keys Processed | Number of custom key records processed by the job. |
These fields map to the Processed Data Summary section on the Job Details page.
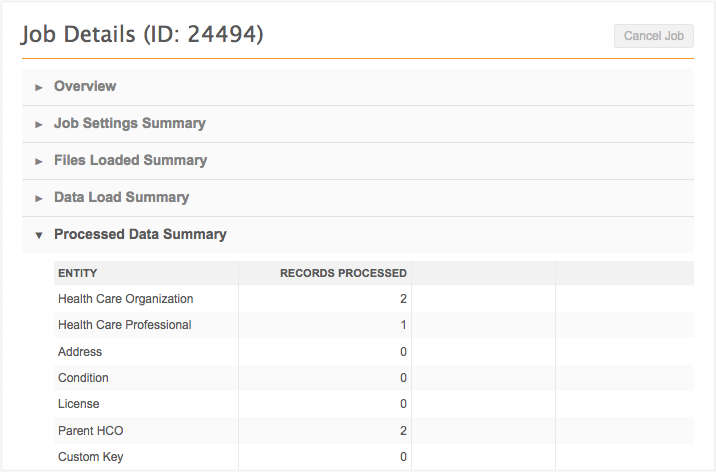
Job Stats table
The Job Stats reporting table contains the following fields.
| Field | Label | Description |
|---|---|---|
| job_id | Job ID | Unique identifier for the job. |
| metric | Metric | The type of action performed during the job. See the Metrics table for possible values. |
| counter | Value | Number of records processed for that particular action. |
Metrics
The metrics field can have many different values. The following tables contain the possible values for metrics.
Unique metrics
These fields display in the Overview section on the Job Details page.
| Field | Alias |
|---|---|
| input.files.processed | Number of Files Processed |
| job.opened.issues | Number of Bad Records |
| export.delta.start | Delta Tag Start |
| export.delta.end | Delta Tag End |
Object metrics
For these metrics, in each field, replace object with the name of a specific object; for example object.added might be hco.added.
Replace object with any of the following Veeva standard objects or custom objects:
- address
- customkey
- hco
- hcp
- license
- parenthco
- custom object (uses the following format: custom_object__c; for example, condition__c.added)
| Field | Alias | Description |
|---|---|---|
| object.added
Example: hco.added |
OBJECT Added
Example: HCO Added |
Number of these objects added during the job. |
| object.candidates.added | OBJECT Candidates Added | Number of candidate records for this object that were added during the job. |
| object.deleted | OBJECT Deleted | Number of these objects that were deleted during the job. |
| object.invalidated | OBJECT Invalidated | Number of these objects that were set to invalid during the job. |
| object.mam.downloaded | OBJECT MAM Downloaded | Number of Veeva OpenData objects that were downloaded to your Network MDM instance because they matched incoming records. For more information, see Enable Match & Download from OpenData. |
| object.merged | OBJECT Merged | Number of these objects that were merged during the job. |
| object.parsed | OBJECT Rows Parsed |
Number of these objects that were loaded and used during the job.
Unrecognized and incorrect VIDs, or extra data is ignored and not included in this count. |
| object.read | OBJECT Rows Read | Number of rows for this object in the .csv file. |
| object.rejected | OBJECT Rejected | Number of objects that were processed and loaded but were rejected because of an issue with the data. |
| object.skipped | OBJECT Not Loaded | Objects that were skipped or merged during the job. Objects are not loaded if they are unmatched when the Action for Unmatched & Suspect Match option in the source subscription is set to No Action. |
| object.updated | OBJECT Updated | Number of these objects that were updated in this job. |
These fields display in either the Data Load Summary or Job Result summary sections of the Job Details page.
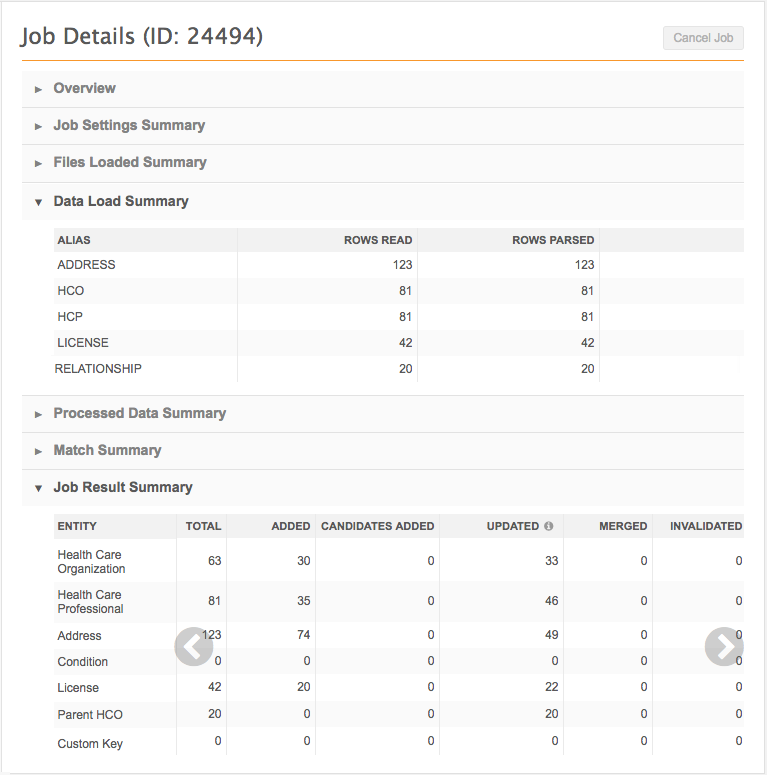
Object match metrics
The match metrics are for entities only. In these metrics, replace object with the name of a specific Veeva object or custom object.
Veeva standard objects
Replace object with either of the following types:
- hco
- hcp
Custom object types
For any custom objects, the object is in the following format: custom_object__c; for example, study__c.match.act.
| Field | Alias (Table Column)? | Description |
|---|---|---|
|
object.match.act Example: hco.match.act |
OBJECT ACT Matches Example: HCO Added |
Number of objects that were merged because of a high confidence match. |
| object.match.ask | OBJECT ASK Matches | Number of objects where a match requires data steward review. |
| object.match.unmatched | OBJECT Not Matched | Number of objects that could not be matched. |
These fields display in the Match Summary section on the Job Details page.
Sample job queries
Job details
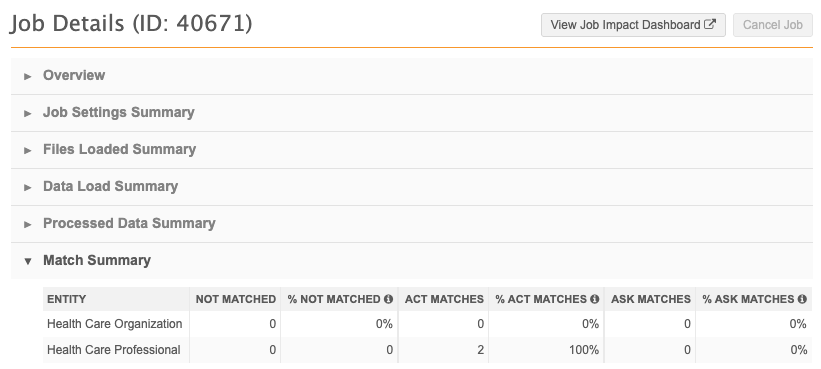
This example reports on the job details and find all the "Added" metrics for a job using the Job ID. In this example, the Job ID is 3.
SELECT
job.job_id,
job_type,
job_system,
subscription,
status,
job_trigger,
metric,
counter
FROM
job LEFT OUTER JOIN job_stats
ON (
job.job_id = job_stats.job_id
AND metric LIKE '%added%'
)
WHERE
job.job_id = 3
Sample results:
Aggregating statistics for average number of records
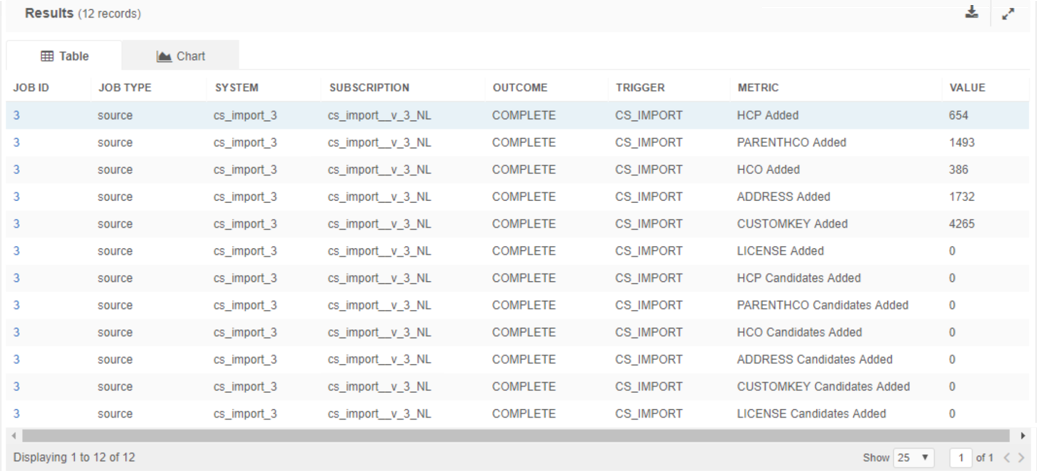
This example reports on the average number of records processed for each job subscription. This example considers completed jobs only.
SELECT
total. "Subscription Type",
total. "Subscription Name",
total. "Data Source",
AVG (
total. "Total Records Processed"
) AS "Average Records Processed"
FROM
(
SELECT
job_id,
job_type AS "Subscription Type",
subscription AS "Subscription Name",
job_system AS "Data Source",
(
hcp_processed + parenthco_processed + hco_processed + address_processed + customkey_processed + license_processed
) AS "Total Records Processed"
FROM
job
WHERE
status = 'COMPLETE'
GROUP BY
job_id,
job_type,
job_system,
subscription,
"Total Records Processed"
) total
GROUP BY
total. "Subscription Type",
total. "Subscription Name",
total. "Data Source" ;
Sample results:
Aggregating statistics for average job runtime
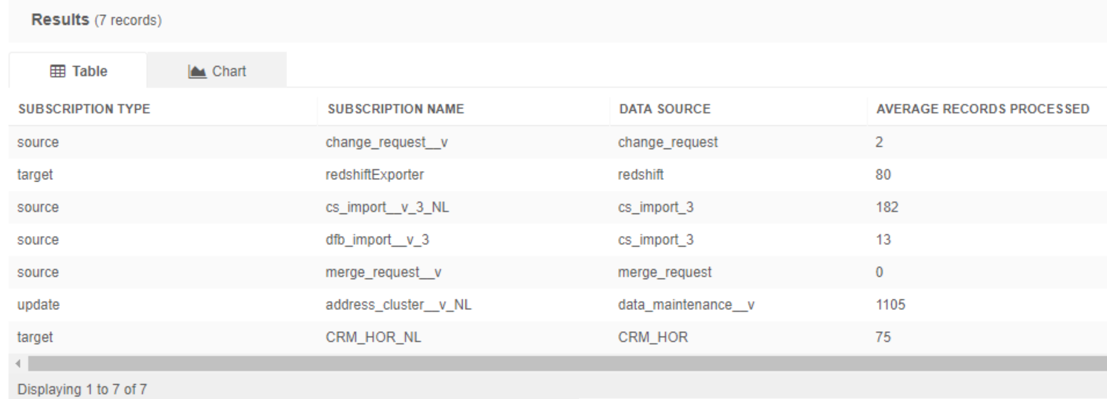
This example reports on the average run time (duration) in seconds for each job subscription. This example considers completed jobs only.
SELECT
total. "Subscription Type",
total. "Subscription Name",
total. "Data Source",
AVG (
total. "Total Time Difference"
) AS "Average Time Difference"
FROM
(
SELECT
job_id,
job_type AS "Subscription Type",
subscription AS "Subscription Name",
job_system AS "Data Source",
datediff (
'second',
start_time,
end_time
) AS "Total Time Difference"
FROM
job
WHERE
status = 'COMPLETE'
GROUP BY
job_id,
job_type,
job_system,
subscription,
"Total Time Difference"
) total
GROUP BY
total. "Subscription Type",
total. "Subscription Name",
total. "Data Source"
Sample results:
Veeva OpenData subscription
This example finds the Veeva OpenData subscription (cs_import) job that added the most HCPs to your Network MDM instance.
SELECT
job.job_id,
job_type,
job_system,
subscription,
status,
job_trigger,
metric,
counter
FROM
job INNER JOIN job_stats
ON job.job_id = job_stats.job_id INNER JOIN (
SELECT
MAX( counter ) AS hcps
FROM
job_stats INNER JOIN job
ON job.job_id = job_stats.job_id
WHERE
metric = 'hcp.added'
AND job_trigger = 'CS_IMPORT'
AND status = 'COMPLETE'
AND counter > 0
) max_hcps_added
ON max_hcps_added.hcps = job_stats.counter
WHERE
metric = 'hcp.added'
AND job_trigger = 'CS_IMPORT'
AND status = 'COMPLETE'
AND counter > 0
Sample results:

Other job reports
- To run the predefined Job Summary report type, see Job summary report. This report is customizable.
- To use report templates to investigate job details, see Working with saved reports.