Data cleansing
DM
Administrators and data managers can define rules to cleanse and standardize data in fields.
Add the data cleansing dictionary to a Network expression in a source subscription or a data model field to update specific field values.
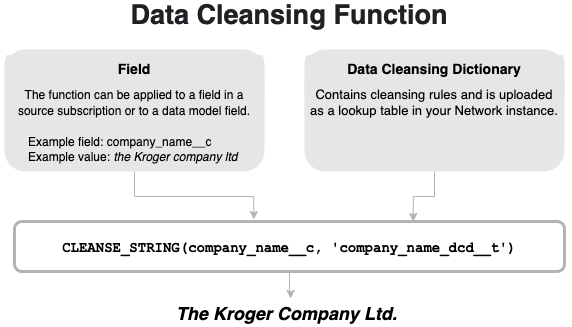
Standardize field values
Cleansing fields helps you to improve the values. This can be helpful for matching and to ensure high data quality in general.
Example use cases:
-
Standardize letter case - Make the first character of each word uppercase (for example, cleanse the Kroger company as The Kroger Company).
-
Standardize names - Standardize the spelling or capitalization of names (for example, cleanse L'oreal to L'Oreal or usa to USA).
-
Formatting legal entities - Use the correct format for all entities (for example, cleanse co to Co.)
-
Remove noise characters or noise words - Remove commas, dashes, parentheses, and so on.
-
Add or remove spaces - Example: Add a space between the number and the measurement (for example, 2 mg).
-
Remove values - Blank out placeholder values ("unknown", "not available", and so on) that users submit.
-
Remove special control characters - Replace characters like tab, returns, line feed, and so on.
Data cleansing process
Cleansing field values involves the following steps:
-
Profile your data to understand where data issues are and understand what cleansing rules are needed to fix these data issues.
- Create cleansing rules in a .csv file. This is your data cleansing dictionary.
-
Upload the .csv file as a lookup table in your Network MDM instance.
-
Create a NEX rule in your source subscription or in a data model field.
If the NEX function is used on a source subscription, the incoming data is cleansed when the job runs. If the NEX rule is applied to a data model field, then the rule triggers and cleanses the data every time the record is updated (for example, in a source subscription or through a DCR).
Important considerations
When you are creating cleansing rules and defining the NEX rule, consider these key practices:
-
Profile the data and understand the issues so you can define the correct cleansing rules.
-
Test the rules to ensure that they cleanse your data in the right way and do not make any unexpected replacements.
-
Store the cleansed value and the original (raw) value in separate fields so you have a record of the change. This will help you to troubleshoot any unexpected replacements.

Create the data cleansing dictionary
In any spreadsheet application, create a .csv file that contains your data cleansing rules. This is your data cleansing dictionary. Each cleansing rule addresses a specific issue.
Example data cleansing dictionary
This data cleansing dictionary, company_name_dcd, contains rules to standardize a field called Company Name. It has rules for specific company names (for example, L'Oreal and RB Health) but it also has rules to standardize capitalization and legal entities for all company names.
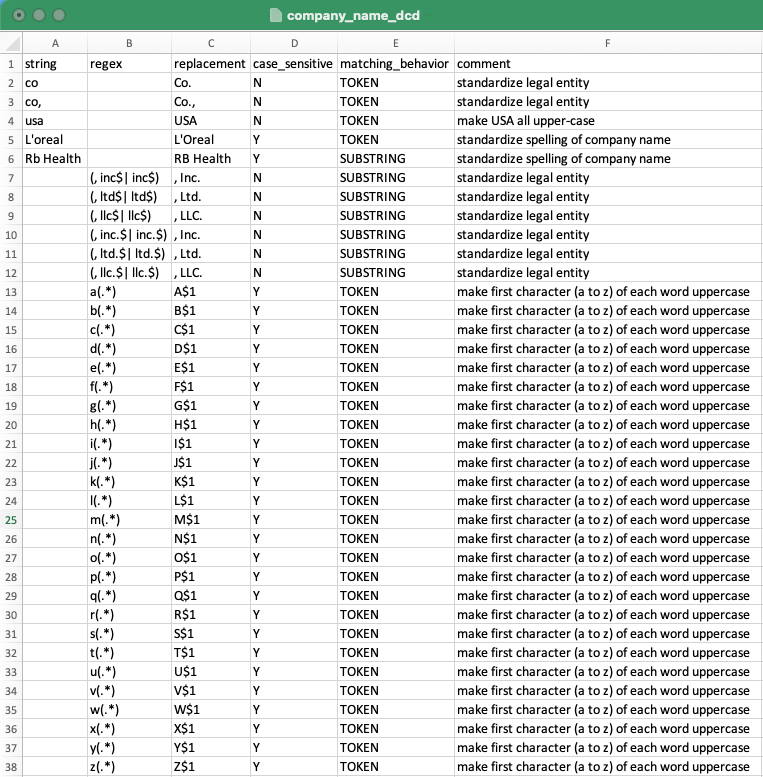
Example data cleansing dictionaries
Mandatory columns
The file must contain the following columns with a value:
-
string or regex - Each rule must include either a string or a regular expression (regex).
Only one of these columns can be populated for a rule. If you have a value in both columns, an error occurs.
-
string - Means that the value is interpreted as a string constant.
-
regex - Means that the value is interpreted as a regular expression.
These two alternative columns are there to make it easier for you if you want to match and replace just on a string. In that case, enter the value into the string column. You do not have to take care of escaping any characters that have a special meaning in regular expressions because everything in that column is treated as a string constant.
However, if you want to use regular expressions to do some advanced matching and replacing, then enter the expression into the regex column. Everything in this column is treated as a regular expression, meaning that you might have to escape some characters depending on your specific expression and use case.
Example
If you specify a dot (.) character in the string column, then this means only every occurrence of a dot is replaced (for example, if you replace (.) with an empty string ("), n.a. is cleansed to na).
However, in regular expression, the dot (.) character has a completely different meaning; it represents any character or number. So, if you replace the
dot (.) character as a regular expression in the regex column with an empty string (") , all characters are replaced ("").
-
-
replacement - The value that you want the matching string or substring to be replaced with. The value can also be empty if you are stripping the field of the value.
Optional columns
The following columns can be included in the file:
-
case_sensititive - Supported values are Y or N. If the column is not included in the file, the default value is N. If you want the rule to match only on a specific case, specify Y in the column.
Case applies to both string column values and regex column values.
Example
These regex rules are similar, but one is case sensitive.
regex,replacement,case_sensitive [a-z],x,Y [a-z],x,N
-
The first rule replaces only all lowercase characters with x.
-
The second rule replaces all characters (regardless of letter case) with x.
-
-
matching_behavior - Identify the type of string or substring to match for replacement. If the column is not included in the file, the default matching behavior is SUBSTRING.
-
SUBSTRING - Every occurrence of the matching string is replaced.
-
TOKEN - Occurrences are replaced only if they are words separated by other words through white spaces. A TOKEN is a sequence of non-white space characters separated by white spaces (blanks, tabs, and so on). If a word is separated by a dash (-), comma (,), parentheses (), or other character, it is not treated as a TOKEN.
-
Tip: Document your cleansing rules by including an optional column to describe each rule.
Example rules
Example 1
This cleansing rule standardizes all occurrences of USA as a token.
| string | regex | replacement | case_sensitive | matching_behavior |
|---|---|---|---|---|
| usa | USA | N | TOKEN |
Column values
-
string - Match the entire string usa.
-
replacement - Replace the matching string with USA.
-
case_sensitive - Replace any occurrence of usa regardless of letter case. This includes usa, Usa, USa, and so on.
-
matching_behavior - TOKEN means only match when usa is an entire word (it is separated by white space). A string that includes usa with other characters; for example, thousand, would not be cleansed as thoUSAnd.
Example 2
This cleansing rule standardizes the legal entity Inc..
| string | regex | replacement | case_sensitive | matching_behavior |
|---|---|---|---|---|
| (, inc$| inc$) | , Inc. | N | SUBSTRING |
Column values
-
regex - Match any occurrence of ,inc or inc at the end of the string.
-
replacement - Replace the matching string with , Inc..
-
case_sensitive - Replace any occurrence of the matching substring regardless of letter case.
-
matching_behavior - SUBSTRING means match any occurrence of the substring.
Sequence of the rules
The sequence of the columns does not matter, but the sequence of the rules does matter. Depending on the sequence, you could get a different result.
Example
In this example, we want to cleanse the string n.a..
Dictionary example 1

Result: With this sequence of cleansing rules, the output is na.
Dictionary example 2

Result: With this sequence of cleansing rules, the output is an empty string.
Ensure that the rules are ordered so that you get the expected output.
Upload the file to Network MDM
When you have created the data cleansing rules, upload the .csv file as a lookup table.
-
In the Admin console, click Data Model > Lookup Tables.
-
Click Create Lookup Table.
-
Type the Table Name and Description, confirm whether the file contains third party data, and upload the .csv file.
The file is validated to ensure that it complies with supported lookup table requirements, but the file is not checked to ensure that the mandatory data cleansing columns are included.
For more information about lookup tables, see Create a lookup table.
-
On the File Preview tab, review the data and click Create Table.
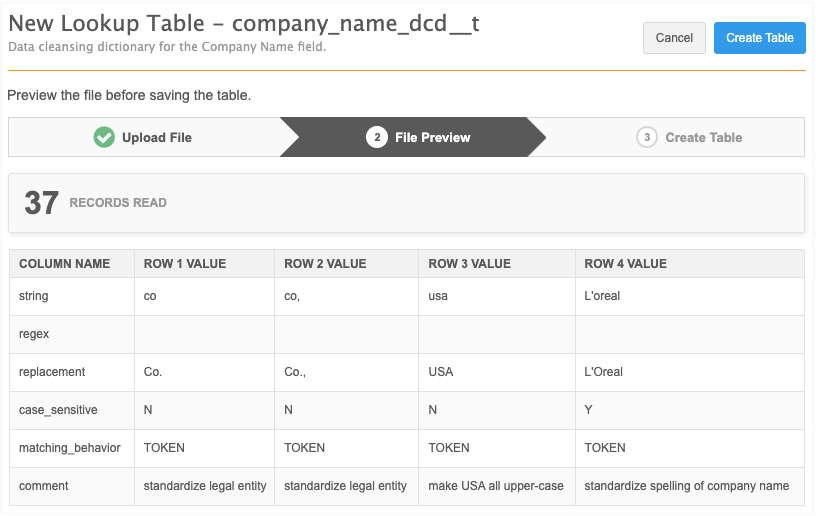
The __t suffix is automatically appended to the table. Remember to add the suffix when you reference the data cleansing dictionary file in the NEX rule.
Edit the dictionary
To change the data cleansing rules, download the lookup table. When the changes are complete you can re-upload the .csv file.
Apply the data cleansing function
The data cleansing function can be applied to a NEX Rule in a source subscription or a on data model field.
NEX rule syntax
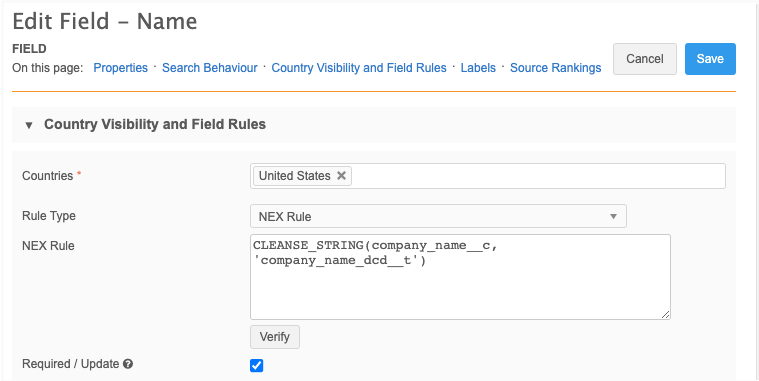
CLEANSE_STRING(<field_name>, '<data_cleansing_dictionary_name>')
-
field_name - The field that will be cleansed.
-
data_cleansing_dictionary_name - The name of the dictionary that you added as a lookup table.
Example rule
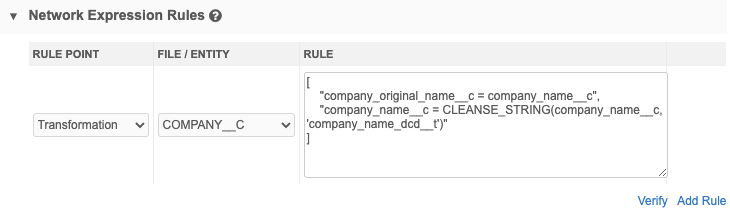
[
"company_original_name__c = company_name__c",
"company_name__c = CLEANSE_STRING(company_name__c, 'company_name_dcd__t')"
]
This rule means that first the existing company name will be saved to a second field, company_original_name__c, and then cleanse the company name. The cleansed name will be stored in the company_name__c field.
To apply data cleansing for a field, add it to a source subscription or a data model field.
-
Source subscription - In the Network Expression Rules section, add the rule.
You will get better match results if you cleanse and standardize the values of the fields that you use in matching (for example, fields like hospital names, company names, product names, and so on). To ensure that the fields are cleansed and standardized before matching, add the rule to the earliest possible stage (File Preparation or Transformation rule points).
-
Data model field - Expand the Country Visibility and Field Rules section and add the NEX rule.
Replacing special characters
You can remove special control characters like tab, returns, line feeds, and so on by replacing them with a defined string (for example, an empty string).
Considerations
-
All special characters must be defined in the regex column (not in the 'string' column).
-
You can replace any special characters supported by Java Regex; only encodings that are supported by Java RegEx can be used. For more information, see the related Java Regex documentation.
-
All backslashes (\) must be escaped with another backslash (for example: "\\t" instead of "\t")
-
The value in the regex column must be in quotes (").

Nulling existing values
If the final outcome of the cleansing is an empty string, then the function will return a NULL value.
Example
This data cleansing rule expects to replace field values that are n/a with an empty string.
string,replacement n/a,
With this cleansing rule, the data cleansing function will return NULL, not an empty string.
To nullify any existing field values through the data cleansing function in a source subscription, add the following property to the Advanced Mode:
"feed.retain.null": "true"
Trimming white space
By default, the string cleansed by the function is trimmed; the whitespace on the left and right of the cleansed string is removed.
Delete the data cleansing dictionary
You can remove the dictionary from the Lookup Tables page. When you remove a data cleansing dictionary, you should also remove the NEX rule. Run time errors will occur for any NEX rule that references a deleted data cleansing dictionary.
Data cleansing errors
When you upload the .csv file as a lookup table, the data cleansing rules are not validated for consistency and completeness. If mandatory information is missing or if there are ambiguities, the data cleansing function will throw a run-time error with details about these issues.
Errors will occur in the following situations:
-
An expected column occurs more than once in the data cleansing dictionary (for example, two columns named string).
-
Values are present in both the string and regex columns.
-
The string and regex columns are both missing from the dictionary (at least one of them is required).
-
The replacement is missing from the dictionary.
-
The lookup table referenced by the data cleansing function does not exist.
-
Unsupported values are present in the columns.
Source subscription
When the data cleansing function is called and an error occurs, the errors display in the Job Error Log section on the Job Details page. The first five errors display.

In this example the following errors occurred:
-
Substring is spelled incorrectly.
-
The case_sensitive column contained an unsupported value (F). Only Y or N are supported.
-
A rule contained values in both the string and regex columns.