Create a data deduplication subscription
DM
Use data deduplication subscriptions to identify duplicate HCP and HCO records in your Network MDM instance.
Supported objects
The following objects are supported for data deduplication jobs:
-
HCPs and HCOs - Only active and valid records are considered.
Both active and inactive sub-objects are considered in the match comparisons to help identify duplicate HCPs and HCOs.
Create a subscription
- In the Admin console, click System Interfaces > Data Maintenance Subscriptions.
- On the Data Maintenance page, click Add Subscription.
- In the Add Subscription dialog, select Data Deduplication and click OK.
- Type a Name and Description for this job that reflects the data that you are analyzing.
- New subscriptions are Enabled by default. For more information, see Inactive subscriptions.
-
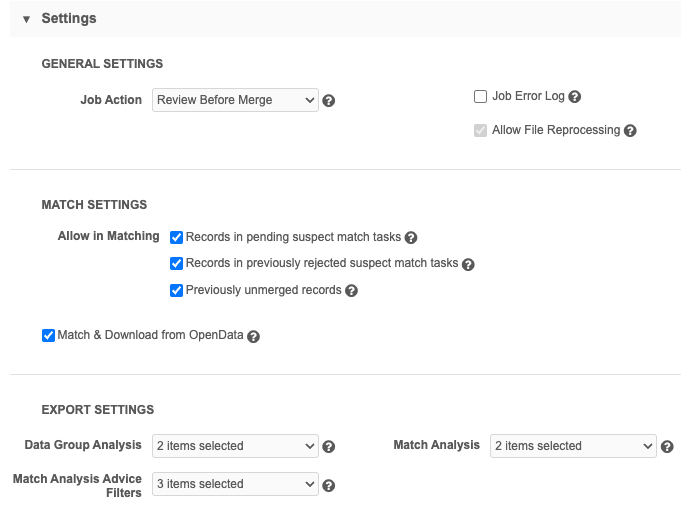
In the Settings section, there are several options to consider:
General settings
-
Job Action - Select how you want Network MDM to process the job:
-
Stop and Don't Merge - Stop the job after the match stage and do not merge records. This is selected by default. Use this option to test the job and ensure that overmatching is not occurring before you apply the updates.
-
Apply Updates & Merge- ACT
 A high confidence match between two records. ACT matches result in a merge without any human review. (strong) matches will be automatically processed. Use when you are confident that the job is matching appropriately.
A high confidence match between two records. ACT matches result in a merge without any human review. (strong) matches will be automatically processed. Use when you are confident that the job is matching appropriately. -
Review Before Merge - Pause the job after the match stage and before the records are merged so that you can export and review the match log for changes. If you enable the Match & Download from OpenData option, you can review the records that will be downloaded from OpenData.
When you are satisfied with the outcome, you can resume the job so the records merge. When you select this option, an email is sent to you when the job pauses so you can review the results. You can resume the paused job from the Job Details page.
-
-
Job Error Log: Create an error log for this job.
If the job produces errors and this setting is on, you can retrieve the error log from Network MDM FTP.
Choose where the logs should be stored:
-
Default - The default error log path is logs/<source system>.
-
Custom - Define a custom directory.
You can define a custom path for the logs and Network MDM will create the folders in FTP when the subscription runs. For details, see Custom error log directory.
-
-
Allow File Reprocessing - Enabled by default and cannot be changed. Data deduplication jobs can run the same file, from the FTP server, multiple times.
Match settings
-
Allow in Matching - Select all options that you want the job to consider for potential matches.
-
Records in pending suspect match tasks
-
Records in previously suspected match task
-
Previously unmerged records
Note: For initial testing, do not select this option.
-
-
Match & Download from OpenData - Select to allow the job to try to match the existing locally managed record to a record in the related OpenData instance.
If strong (ACT) matches are found, the job will download the record from OpenData and the locally managed record will be merged.
Tip: To ensure that the highest ranked match is found, enable the Consider records in OpenData Instances setting (General Settings). The match process will continue looking for a superior match in the OpenData instance even if a match has already been found in your Network MDM instance. For more information, see Match & Download from OpenData.
Export settings
Choose to export match logs.
-
Export Data Group Analysis - Select to export data group logs for HCOs and HCPs.
This is helpful for analyzing the results while you are testing the effectiveness of the Data Deduplication job.
-
Export Match Analysis - Export match logs for HCOs and HCPs.
This is helpful for analyzing the results while you are testing the effectiveness of the Data Deduplication job.
-
Match Analysis Advice Filters - Filter the exported match log by result type: ACT, ASK, or Unmatched results.
-
- In the HCP Subset Options and HCO Subset Options sections, identify the records that you want to compare.
- No Records - Use to indicate that no HCPs will be compared during the job.
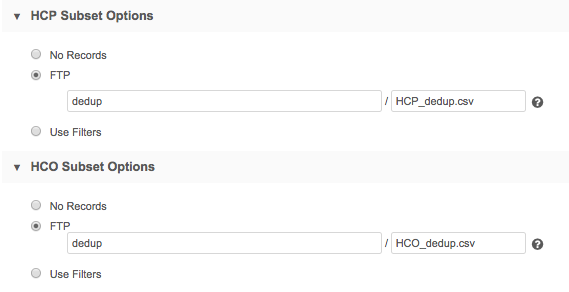
- FTP - Create a .csv file with a list of Network IDs and add it to an FTP site. Specify the FTP directory where Network MDM can retrieve the file.
For information about accessing the files in your Network MDM file system, see File Explorer.
File requirements:
One column only that contains the list of Network IDs
- Column header is optional and must not have any other characters around the text
- Network IDs must be listed in separate rows
- Double quotation marks ("") around Network IDs are permitted
- No extra characters; for example, commas (,) after Network IDs
- File name must be exactly the same format as it is on the FTP site; capitalization matters (for example, VIDS.csv is not the same as VIDs.csv)
- Notes:
- One file can contain both HCOs and HCPs. Identify it in either the HCP Subset Options or the HCO Subset Options section.
- If you use separate files, the file names can be different, but the FTP path must be the same.
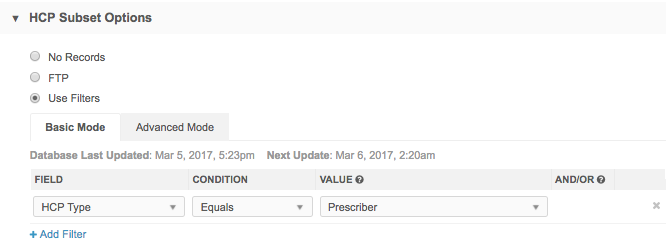
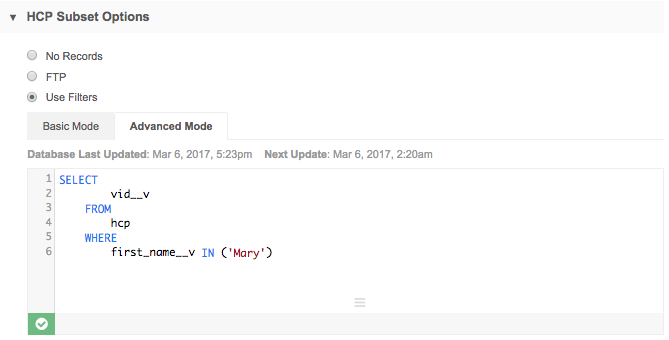
Use Filters - Use the filters in Basic Mode or create a SQL query in Advanced Mode to identify the records that you want to compare during the job.
Tip: To use filters, Network MDM Reporting must be available.
An advanced SQL query must return a list of Network IDs only. The SQL query can contain both HCP and HCO records. Note that even if No Records has been selected for HCPs or HCOs, if your query returns both HCO and HCP records, they will be included in the job.
Note: If a filter defines a sub-object (Address, License, Parent HCO), the owning HCO or HCP is identified and that VID is used in the matching process. All fields and sub-objects on a record are used to identify possible duplicates.
The reporting database identifies the records that are selected in Basic or Advanced queries. You might find a discrepancy between what reports or filters indicate versus the actual status of records in the instance. When you are analyzing the remaining duplicate records, take note of when the reporting database was last updated for your instance.
-
In the Match Configuration section, define match rules and data groups by country and entity type for this job. If you have records for a country where match rules are not defined, the data deduplication process cannot match those records so the records are skipped.
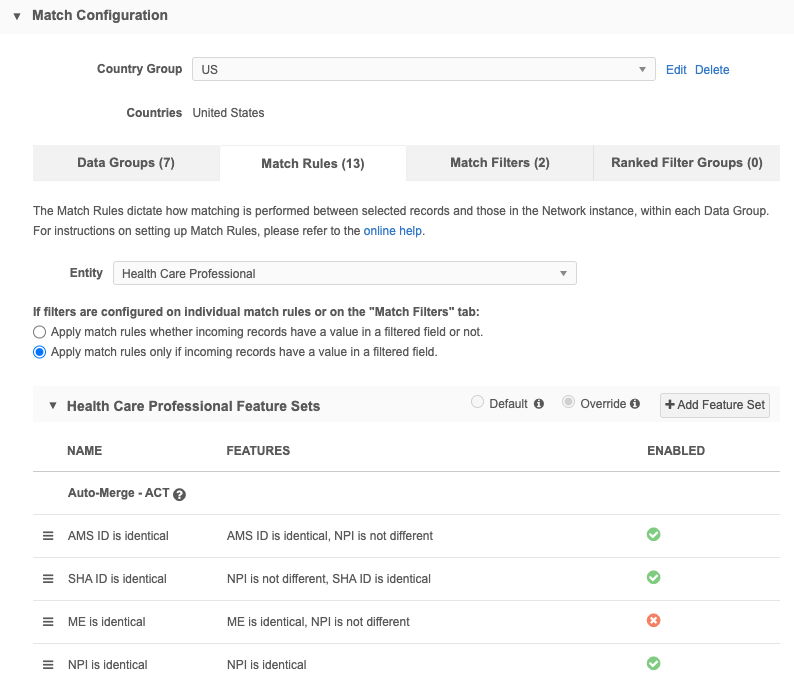
Match configurations contain the following tabs:
-
Data Groups - Restrict the set of records to compare.
Data groups should be generic enough to include all possible matches, but cannot include more than 1,000 records.
-
Match rules- Provides detailed rules to compare records.
-
Match filters - Conditions that apply to all defined match rules to include or exclude specific records from being considered for match pairs.
-
Ranked filter groups - Match conditions that are applied to the subscription to include or exclude records that are considered for matching.
For detailed information, refer to Match configuration.
Applying filters to incoming records
If filters are configured for individual match rules or all match rules, the rules can consider incoming records even if they are missing the field value of the filter.
- Apply match rules whether incoming records have a value in a filtered field or not - Select to allow incoming records with empty or missing field values to be considered for match rules.
This is the default option for all new match rules.
-
Apply match rules only if incoming records have a value in a filtered field - Select if the incoming data is robust and has values in filtered fields
This is the default for existing match rules.
These options are supported when the filter function is Include. Exclude functions require the records to have the specified field and value.
Network MDM provides default data groups and match rules that can be used or modified for your instance. These are the same defaults used by source subscriptions.
For details, see Match configuration.
-
-
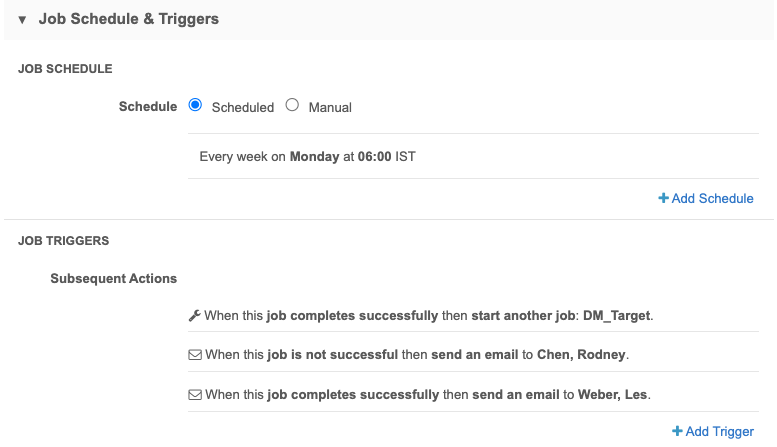
In the Job Schedule & Triggers section, define the schedule for the job and any subsequent actions that will start when this job finishes.
Job Schedule - Run the subscription manually or on a scheduled basis. If you select Manual, the subscription only runs when you click the Start Job button on the subscription page. During testing, select Manual; scheduled jobs should not be paused.
Job Triggers - Trigger other actions to start after a job runs.
Available triggers:
- Send email - Specify users that should be notified for successful and unsuccessful job outcomes.
- Start a job - Start a subsequent job when this job successfully completes.
For more information, see Subscription job triggers.
- Save your changes.
Next steps
Run the job. If you set the Review Before Merge option, you can review the matches before records are merged. For more details, see Run and pause data deduplication jobs.