Match logs
DM
When you create source subscriptions and data duplication maintenance subscriptions, you can specify options to assist in analyzing and tracking match data.
Data group analysis log
Data groups
Network MDM provides default match rules![]() A definition that determines which fields in a record are a possible match and when a record comparison is considered a suspect match. See features and feature sets. for every country. The match rules include data groups so every subscription has data groups that can be used or modified. You can also add your own data groups.
A definition that determines which fields in a record are a possible match and when a record comparison is considered a suspect match. See features and feature sets. for every country. The match rules include data groups so every subscription has data groups that can be used or modified. You can also add your own data groups.
For more information about data groups, considerations, and recommendations, see Create data groups.
Logs
You can export a log file that identifies the different data group![]() A component of the match process that groups data into blocks to reduce the overall amount of data to compare. definitions that have been created as part of this job. It also identifies the different data groups that exist for each definition, in both the incoming data as well as your Network MDM instance.
A component of the match process that groups data into blocks to reduce the overall amount of data to compare. definitions that have been created as part of this job. It also identifies the different data groups that exist for each definition, in both the incoming data as well as your Network MDM instance.
Export the logs
In the subscription settings, you can choose to export the data group details to the outbound folder on your FTP server (File Explorer).
-
In the Export Settings section, expand the Data Group Analysis option.
-
Select the objects to log. Veeva standard objects and custom objects (source subscriptions only) are supported.

When the job runs, the data group analysis is exported to a .csv file for each selected object.
Log name
The naming convention for the log file is: <subscription_name><Object>-DATA-GROUP-ANALYSIS-<date>-job-xxx.csv.
Data group details

The exported .csv file contains the following information:
| Column Header | Details |
|---|---|
| Key Attributes |
The data group definition. The data groups that are created are the unique combination of these fields.
Example data group definition first_name__v + last_name__v + primary_country__v. The definition might create the following data groups:
One definition can create many data groups. Note: Because all matching is done within a country, primary_country__v is automatically added to each data group definition. This isn't visible and cannot be changed. |
| Number of Blocks |
The number of distinct data groups created for the definition. If zero (0) data groups are created, the search didn't find any records for that data group definition. |
| Source Size | Columns for source minimum, maximum, and median size identify how the records in the incoming data were grouped based on the data group definition. |
| Master Size | Columns for master minimum, maximum, and median size identify how the records were grouped in your Network MDM instance based on the data group definition. |
Data group performance
In addition, the following columns can help you understand how the data groups are performing.
| Column Header | Details |
|---|---|
| Search Time |
The time it took to create the data groups. If blocks are taking a long time to create, you might need to reconfigure your data groups. |
| Number of entities matched by this group | Displays the number of matches that were found by the group. |
| Number of entitles belonging to this group but without a winning match | Matches were found for these groups, but the records weren't matched within in the group. |
| Number of entities not belonging to this group | Displays the groups that are not finding matches. Use this information to understand which data groups are the least helpful. |
Use this information to see which groups produced matches and which ones did not.
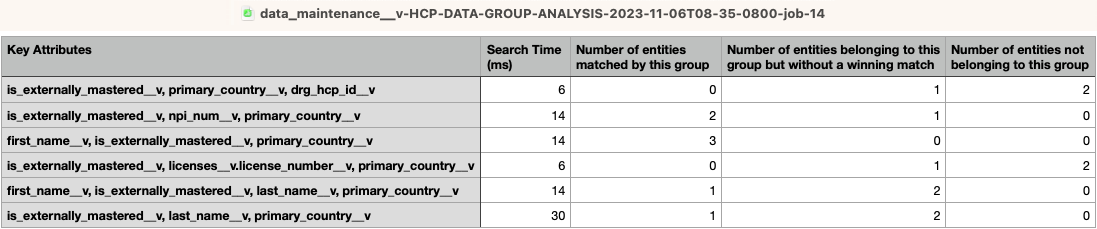
Example
Using the data in this log, we can make the following conclusions about the groups:
-
The first data group didn't take long to create but it didn't find any matches. It is not a useful group.
-
The middle rows indicate multiple data groups found matches. Not all of them may be required.
-
The last data group took a much longer time to create and didn't yield any matches. It should be removed.
Match analysis log
Use the Match Analysis list in source subscriptions and data deduplication subscriptions to export match results to the outbound folder on your FTP server (File Explorer).
The list contains all Veeva standard and objects, sub-objects, and relationship objects that are enabled in your Network MDM instance.
Custom objects are supported for source subscriptions only.
Exported log files
When the job runs, the match analysis is exported to a .csv file for each object. Separate logs files are created for sub-objects.
File name
The naming convention of each .csv file is: <subscription_name><object2>-MATCH+DATA-GROUP-ANALYSIS-<date>-job-xxx.csv.
Details
The file provides the following details:
-
The records that matched.
-
The rule that found the match.
-
Details about the incoming data.
-
Details about the data in the matching record.
-
All records found in the incoming file that did not match.
Match details
The match analysis log contains the following columns of information:
| Column Header | Details | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rule Name | The name of the matching feature set |
|||||||||||||||||||||
| Features | The actual feature names included in the feature set shown in the previous column, or blank, if no match was found. | |||||||||||||||||||||
| Advice |
Indicates the result of this rule:
|
|||||||||||||||||||||
| Match Filters in Use |
Indicates if a match filter was used when the match pair was found.
Values can be one of the following:
|
|||||||||||||||||||||
| Rank Group |
Display the ranked group filter name where the match was found.
The column is empty if ranked group filters do not exist, or the match pair was not found in a ranked group. |
|||||||||||||||||||||
| Mode |
Indicates where or how the match was found.
|
|||||||||||||||||||||
| Source Archive | The temporary ID assigned to the incoming record when the file is loaded. | |||||||||||||||||||||
| Source Type | The name of system used by source subscription. | |||||||||||||||||||||
| Source Value |
The value of the matching key.
Tip: Use the values in the Source Value and Source Item Type columns to understand and identify key matches that occur during jobs. |
|||||||||||||||||||||
| Source Item Type | The "item" value of the matching custom key. This can help you identify the exact key that matched. | |||||||||||||||||||||
| Source Country | The primary country of the incoming record. | |||||||||||||||||||||
| Match ID | The ID of the matching record including the instance number. (This could be a Network ID from the local instance or master instance, or a source archive ID if a match was found within the incoming file). |
|||||||||||||||||||||
| Numeric Match ID | The Network ID or archive ID. | |||||||||||||||||||||
| Instance | The instance where the matching Network ID was found. | |||||||||||||||||||||
| Match Country | The primary country of the matching record. | |||||||||||||||||||||
| Source field_namev | The value in this field in the incoming file. | |||||||||||||||||||||
| Match field_namev | The value in this field in the matching record. | |||||||||||||||||||||
| Data Group: field names | All data groups created by this job are listed in the remaining columns. For more information, see the section below on Data group information. |
In fields with multiple values, a tilde (~) is used to separate each attribute. In fields with multiple rows, a tilde (~) is used instead of a carriage return.

Add fields to the match log
By default, the log shows both match and source values for all fields included in the match rules for that subscription.
You can include additional columns for entity and sub-object fields in the log.
Advanced setting
Use this advanced setting to add more values to that log:
job.match.additionalColumns
Considerations
-
Source files - For the fields and values to be shown in the match log, the fields must either be included in the match rules, or in both data groups and the
job.match.additionalColumnnsetting. -
Matches - Any rule that matches will display the field and value in the match log if the field is included in the
job.match.additionalColumnssetting.
Advanced setting format
Requirements
-
Delimiter - List the fields in the property separated by commas (,).
-
Field names - The name of the field and child field must be used exactly as it is used in the data model.
-
Case - Field names are case-sensitive.
Each column name should be in the following format:
Match or Source: fieldName or fieldName.childFieldNameNote: If the column name is not in the correct format, the subscription job might fail.
Examples
- fieldName = addresses__v
- childFieldName = thoroughfare__v
- childFieldName = locality__v
To show the match value for the thoroughfare__v sub-object field:
"job.match.additionalColumns": "Match:addresses__v.thoroughfare__v"
To show both the source and match values for the thoroughfare__v and locality__v fields:
"job.match.additionalColumns": "Match:addresses__v.thoroughfare__v,Match:addresses__v.locality__v, Source:addresses__v.thoroughfare__v,Source:addresses__v.locality__v"
Any field from an HCP, HCO, or sub-object can be included in the match log but only attributes from records in the instance are shown. Additional columns might display for fields used in the match rules for other countries (ZZ) or China (CN). The additional columns will be added to the match logs for all entities (HCO and HCP).
For unmatched records, the columns will be empty.
Add fields by entity type
Additional columns of fields can also be added for each entity type (HCO and HCP).
Each column name should be in the following format:
HCO{Match or Source: fieldName or fieldName.childFieldName}
or
HCP{Match or Source: fieldName or fieldName.childFieldName}
A comma-separated list of additional columns can be defined for each entity type. The entity types must be separated by a semi-colon (;).
Example
"job.match.additionalColumns": "HCO{Match:primary_country__v};HCP{Source:addresses__v.vid__v, Match:first_name__v,Match:primary_country__v,Match:addresses__v.address_line_1__v}"Add Network IDs to the match log
The Network IDs of matched addresses can also be included in the match log.
Use the following advanced setting and value:
"job.match.additionalColumns":"Match:addresses__v.vid__v"
To add this property to the source subscription, click Advanced Mode and include it in the Edit Module Properties dialog.
Data group information
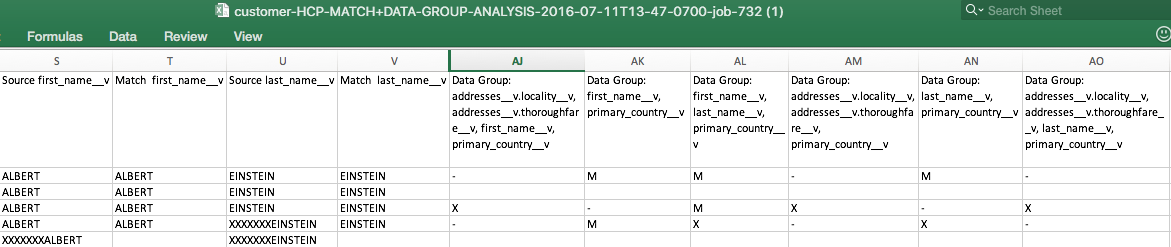
The match log analysis file includes information about the data groups that contain the matching records and which data group produced the winning match. For any records with ACT or ASK outcomes, the following information is included in the match analysis file:
- (X) – shows the data groups that each record was placed in.
- (-) – shows the data groups that each record was not placed in.
- (M) – shows the data groups that produced the match.
Note: If you have "key matching" turned on in a source subscription, and the incoming file matches solely on keys, the new data group columns do not display in the log. When a record matches on an external key, it doesn't go through the rest of the matching process; no data groups are created and the regular rules are not run.
For more information about data groups and examples of fields with null values, see Create data groups.
Sub-object match logs
Match logs for sub-objects help administrators and data managers track the sub-objects that are matched and merged during a source subscription job.
A separate log file is created for each sub-object. Sub-object match logs can be used independently of sub-object source deduplication.
Supported objects
All Veeva standard and custom sub-objects are supported.
Create a match log
To create a sub-object match log,
Select the object from the Match Analysis list.
Select the Save Changes to the Database.
The logs are created when the source subscription job completes.
Note: Job performance will slow if match logs are exported for all sub-objects.
Exported match log
Match analysis logs are exported as a .csv file to the outbound folder in your FTP server. Each log provides details on which records matched and how it matched. It also includes details about both the incoming data and the data in the matching record.
The sub-object match analysis log contains the following columns of information:
- Reason / Rule Name - The method the match was found: N/A (Key Match), Field Match (duplicate detection rules), Network Entity ID (matched using the Network ID).
- Advice: ACT, ASK, or UNMATCHED. Sub-objects are only ACT or UNMATCHED.
- Entity id - The Network ID of the matching main object.
- Entity Type - The entity type of the main object; either HCP or HCO.
- Source Address ID - The Network ID or Archive ID of the source object.
- Match Address VID - The Network ID or Archive ID of the matching object.
- Source Custom Key - The custom keys of the source object.
- Match Custom Key - The custom keys of the matching object.
Example
Review the example to see the address match analysis log that is created when the following HCP and address data is loaded into Network MDM.
HCP
The HCP.csv file contains the following information:
| ID | first_name__v | last_name__v | npi_num__v | primary_country__v |
|---|---|---|---|---|
| 2152 | Chris | Woodson | 9251950021 | US |
| 992 | Christopher | Woodson | 9251950021 | US |
When the subscription runs, Network MDM matches these HCP records together using the NPI number
Address
The address.csv file contains the following information:
| Address | ID | Address_ID | address_Line_1 | locality__v | administrative_area__v | country__v | postal_code__v |
|---|---|---|---|---|---|---|---|
| 1 | 2152 | 129889 | 15 York St | New York | US-NY | US | 52152 |
| 2 | 2152 | 129889 | 15 York St | New York | US-NY | US | 52152 |
| 3 | 2152 | 129890 | 62 York St | New York | US-NY | US | 52152 |
| 4 | 2152 | 129891 | 62 York St | New York | US-NY | US | 52152 |
| 5 | 992 | 129892 | 62 York St | New York | US-NY | US | 52152 |
| 6 | 992 | 129892 | 62 York St | New York | US-NY | US | 52152 |
| 7 | 992 | 129894 | 52 Water St | New York | US-NY | US | 2150 |
Note: The Address column is added to help explain this example - it is not part of the .csv file.
Address match log
The exported match log tells you what existing address the incoming addresses matched on.

Results
Address 1 and 2 - Matched using key match because the custom keys are identical.
The Advice column displays UNMATCHED because the record did not match an existing record in Network MDM.
A new address record is created in Network MDM.
The match log displays one entry. If addresses are matched using key matching the match log shows one entry; the new address.
Address 3 - There were no existing records in Network MDM for this address to match, so the match log shows it as UNMATCHED; a new record is created in Network MDM.
Addresses 4, 5, and 6 -Matched to Address 3 using duplicate detection rules.
The Advice column displays ACT.
The Match Custom Key column displays Address 3's custom key displays as the matching key.
- Address 7 - Umatched. It did not match any existing records in Network MDM. A new record for the address is created in Network MDM.
Log file names
When sub-object match logs are exported, they are zipped together in one file.
Compressed file
File Name: <System>-CHILD-MATCH-ANALYSIS-<Date and Time Stamp>-job-<Job ID>.zip
Example: SAP-CHILD-MATCH-ANALYSIS-2017-05-15T09-29-0700-job-5001.zip
Sub-object match log
Extract the file to view each sub-object match log.
File Name: <System>-<Sub-ObjectName>-MATCH-ANALYSIS-<Date and Time Stamp>-job-<Job ID>.csv
Example: SAP-ADDRESS-MATCH-ANALYSIS-2017-05-15T09-29-0700-job-5001.csv
File retention
Sub-object match logs are deleted from the FTP folder after three days.
Advanced job property
When source subscriptions run, Network MDM uses the following advanced property for match analysis logs:
"job.match.export": ""By default, there is no value.
Supported values
The value can be any combination of objects:
HCP
HCO
Address
License
ParentHCO
custom object
Example
"job.match.export": "HCP,HCO,Address,License,ParentHCO". Selecting the Match Analysis log options in the source subscription populate this job property.
Analyze the logs with Network MDM Reports
Administrators and data managers can run reports on match logs. The logs contain many records, so using reports makes it easier to analyze the data to discover the effectiveness of your match rules and data groups. For more information, see Match log report.
Log retention
Logs that have been created in the past three days are immediately available for use in Network MDM Reports.
Logs that are older than three days can be retrieved using the Analyze Match Log button on the Job Details page. The logs can be retrieved only if you chose to export them when the job initially ran.