Match & Download from Veeva OpenData
DM
During data load and data deduplication jobs, you can automatically match local records against records in Veeva OpenData and download the matched records to your Network MDM instance.
-
Source subscriptions - Incoming records are matched against records in OpenData.
-
Data deduplication subscriptions - Existing records are matched against records in OpenData.
Supported matches
-
When local records ACT match to a record in the OpenData instance, the record is downloaded to your Network MDM instance.
Weak or suspect matches (ASK matches) are not produced by this feature.
Country support
This feature is available for all OpenData countries.
Considerations for China
To comply with privacy regulations, the feature is supported for the following countries/regions only on instances that are hosted in China:
-
China
-
Hong Kong
-
Macao
See POD details to learn where your instance is hosted. Your POD is listed on the General Settings page (Settings).
Prerequisites
To match records against Veeva OpenData, you must have a subscription for Veeva OpenData for that country so those records are available for match consideration.
The settings in the OpenData subscription; however, are not used for this feature. If an incoming record is matched with a record in Veeva OpenData, only the OpenData record is downloaded; no parent HCO records are downloaded with the record.
Enable the feature
This feature can be used in source subscriptions and data deduplication subscriptions.
Source subscriptions
To enable in a source subscription configuration, select the following settings:
Job Run Outcome section:
-
Save Changes to the Database – downloads the matched records to your Network MDM instance
Match Settings section:
- Match & Download from OpenData – ACT
 A high confidence match between two records. ACT matches result in a merge without any human review. matches your data against Veeva OpenData
A high confidence match between two records. ACT matches result in a merge without any human review. matches your data against Veeva OpenData
These settings can also be defined when you click Start Job.
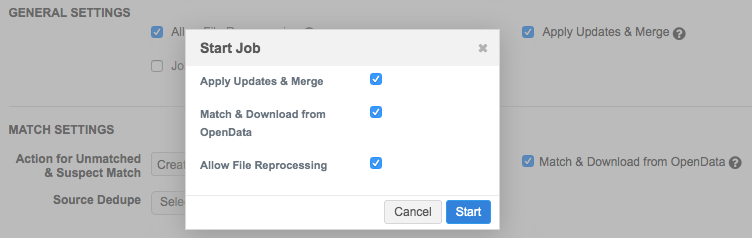
Data deduplication subscription
One of the following settings must be enabled in the configuration:
General Settings section:
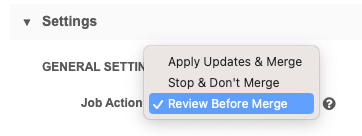
One of the following options must be set for the Job Action:
-
Apply Updates & Merge – downloads the matched records to your Network MDM instance
-
Review before merge - Pause the job after the match stage and before the records are merged so that you can review the match log for changes. When you are satisfied with the outcome, you can resume the job so the records merge.
Match Settings section:
- Match & Download from OpenData – ACT A high confidence match between two records. ACT matches result in a merge without any human review. matches your data against Veeva OpenData
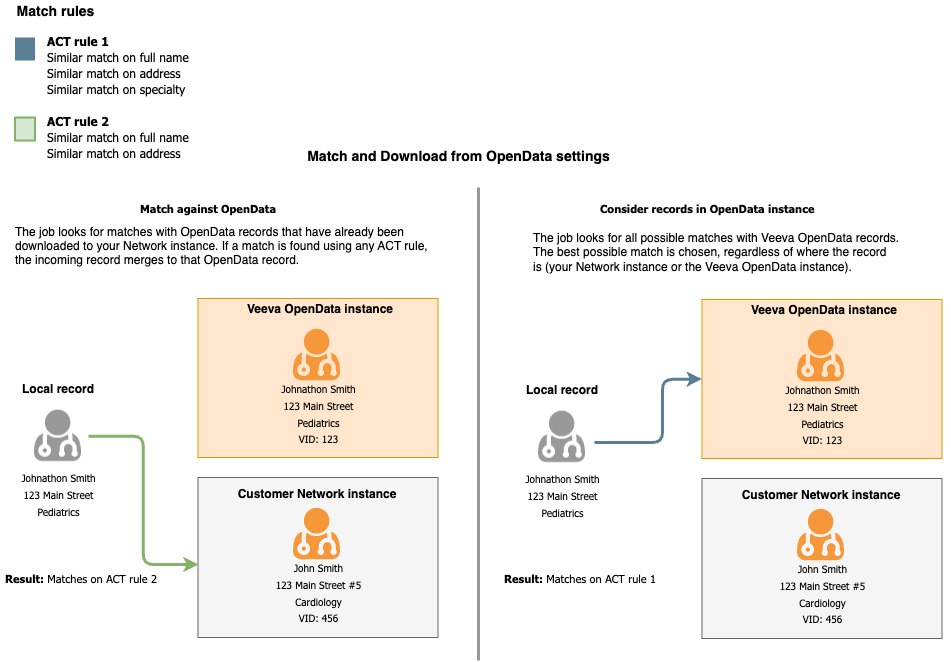
When you enable these settings, the match process first looks for matches to OpenData records that exist in your Network MDM instance. If a match is found using any of the ACT match rules, the incoming record will be merged into that Veeva OpenData record.
Additional match options
Administrators can enable the Consider records in OpenData Instances setting that directs the match process to keep looking the highest ranked match.
When this setting is used, Network MDM will continue looking for a superior match in the Veeva OpenData instance even if a match has already been found in your Network MDM instance.
Enable the setting
To make this option available in your Network MDM instance, contact Veeva Support.
After it is enabled by Veeva Support, administrators can select the Consider records in OpenData Instances setting on the General Settings page.
Downloaded records limit
A limit of 5000 records can be downloaded from OpenData when each source subscription or data deduplication job runs.
The limit is enabled only if you purchase OpenData per record for a country to ensure that you do not accidentally match and download OpenData records in bulk.
Note: This limit does not apply to ELA customers.
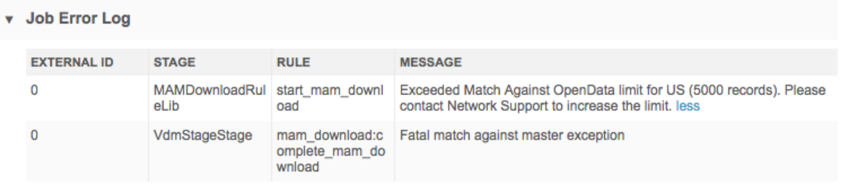
Exceeding the record limit
When the job runs, incoming records that are matched with records in Veeva OpenData are downloaded to your Network MDM instance.
If you buy OpenData per record in that country and the job tries to download more than 5000 matched records, the job will fail; no records will be created or updated in your Network MDM instance. The Job Error Log advises that the number of matched records exceeds the limit of records that can be downloaded for the country.
To increase the limit or discuss your subscription options, contact Veeva Support.
Reporting on downloaded records
Users with access to advanced reporting can create a query to view the number of records that were downloaded from Veeva OpenData for any job. A metric, {object_name}.mam.downloaded, has been added to the Job stats reporting table to support this query. Use the job ID to create your query.
Example query
SELECT
*
FROM
job_stats
WHERE
job_id = '3496'
Match considerations
Fuzzy matching in source subscriptions
In source subscription jobs, matches are identified using the following:
-
key matching (local records)
-
fuzzy matching (the match rules that are defined in the Match Configuration section of the subscription)
If fuzzy match is not enabled for the subscription (in Advanced Mode, the property job.match.fuzzyMatch is set to false) but Match & Download from OpenData is enabled, the following behavior occurs:
-
Network MDM uses keys (custom keys and alternate keys) to match local records
-
Network MDM uses the match rules defined in the source subscription to find matches between local records and records in the Veeva OpenData instance.
-
If Network IDs are included in the source file, the Network IDs are used in the key matching to look for matches between local records and records in the Veeva OpenData instance.
This could result in a match being found to a record in Veeva OpenData, and then the record will be downloaded to your Network MDM instance. If the Veeva OpenData record was in your Network MDM instance, it will be updated by the resulting merge or download.
Downloading unsubscribed Veeva OpenData records
Veeva OpenData records can be unsubscribed. If Match & Download from OpenData is enabled, the unsubscribed records can be matched and downloaded to your Network MDM instance again.
-
Fuzzy match - When using fuzzy match to match against OpenData, unsubscribed OpenData records can be downloaded.
-
Key match - If the incoming file includes Network IDs, Network MDM uses them to key/ID match. When the match is identified by Network ID, a match will not be found.
Moving custom keys between merged records
If your source subscription creates a match and a Veeva OpenData record is downloaded to your Network MDM instance, a custom key (created by the subscription job) is added to the downloaded record. If the record that is downloaded is the merge loser, it will still be updated with an active custom key. The winning record should contain the custom key because it indicates the source that contributed data.
To inactivate the custom key on the losing record and add it to the winning record, perform a Sync with OpenData job from the search results or the Data Lineage page. For more information, see Sync with OpenData.
Match logs
Export the match logs to review the records that were matched in the OpenData instance. Only ACT matches are identified for matches found to records OpenData instances.
For details, see Match logs.