Run and pause data deduplication
DM
Data deduplication jobs can be scheduled or manually run.
Review merges
When you created the data deduplication job, if you chose the Review Before Merge job action, the job will pause so that you can review the records before they are merged.
After the job runs, review the summary information on the Job Details page.
Running a data deduplication job
To manually run job:
- On the Admin Console, click System Interfaces > Data Maintenance Subscriptions.
- On the Data Maintenance Subscriptions page, click the name of the job from the list.
- On the Details page, click Start Job.
- In the Start Job confirmation dialog, click Start.
When the job completes, the Job History section displays at the bottom of the job page. There are separate columns for match and merge actions that occurred during the job. If no records were merged during the job, or you chose not to apply merges, data does not display in the merge columns.
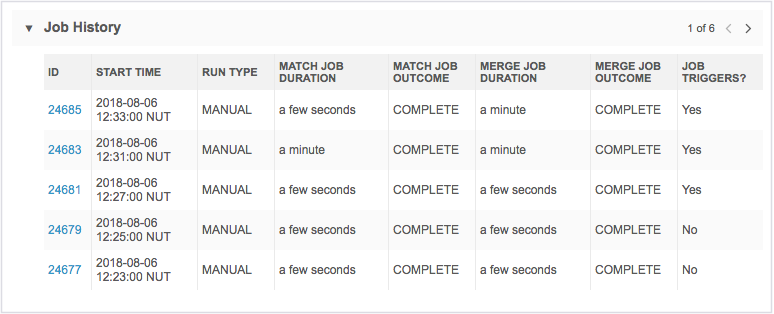
Suspended jobs
If the server is busy with multiple jobs, the match stage of the job will be suspended until the server is free. This ensures that higher priority data loading jobs are not impacted by this maintenance job.
The job status in the Match Job Outcome will display Suspended.
Note: The merge stage of the job does not go into suspended mode.
Identify merges
When a record is merge during a data deduplication job, it is noted in the record's revision history (Profile > Revision History) so you can easily identify the source of the merge.
Pausing jobs
You can review the matches before records are merged. Use the Review before Merge option in job Settings section to stop a job after the match stage.
If you ran the job manually, when the job pauses an email notifies you when the data is available to review.
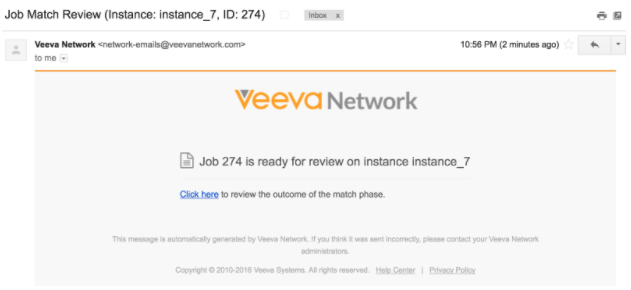
Click the link in the email to navigate to the Job Details page.
Now that you've identified the records to compare, run the data deduplication job as many times as necessary until no further duplicates are found for that set of records.
Logs
Export the match and data group logs so that you have match outcomes to review. Reviewing the logs also confirms to you that the job is performing as expected.
Scheduled jobs
Pausing jobs is not recommended for scheduled jobs. If the data deduplication job was scheduled, the job pauses but an email notification is not sent.
Resuming jobs
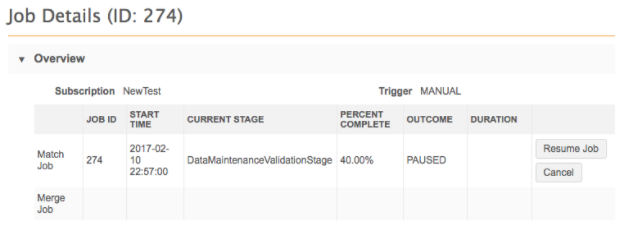
When you are confident that the matches are accurate, click Resume Job on the Job Details page to complete the job by merging the records.
Promptly resuming the job is recommended because the list of records is static and does not consider that those records might have changed since the job initially ran.
If changes are required to the match rules, cancel the job, update the match configuration, and run the job again.
Considerations for Network MDM upgrades
Paused jobs will not be canceled during Network MDM upgrades. They will remain in a paused state, waiting for user review.
Data deduplication job details
When a data deduplication job completes, users can view more details on the job page. Click the job ID in the Job History section.
The Job Details page provides summary information for match and merge actions. If the merge stage of the job did not occur, no merge section displays.
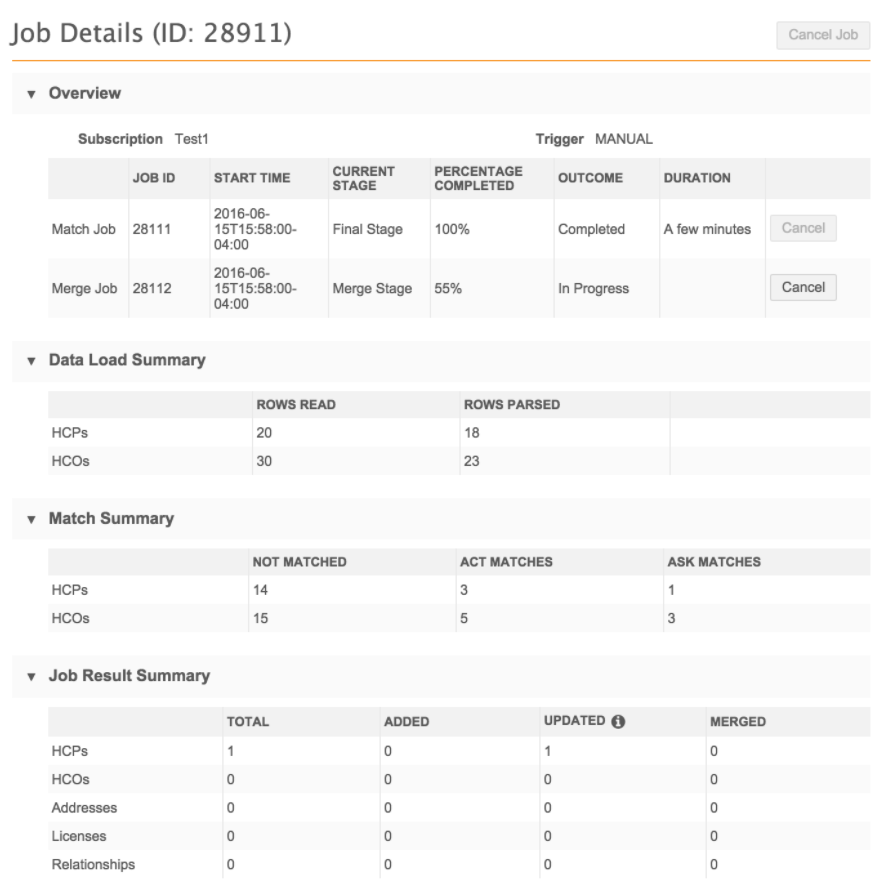
Data Load Summary
The number of rows that were loaded and how many were processed.
-
Rows Read - The number of rows in the file.
If you used one FTP file for both HCP and HCO Network IDs, the count in the Rows Read column indicates the number of rows in that file, even if one file contains both HCPs and HCOs. The statistics display in the row (HCP or HCO) that was used to list the file name on the job configuration page.
-
Rows Parsed - Displays how many records for that entity were loaded and used.
Unrecognized and incorrect Network IDs, or extraneous data, is ignored and not included in the Rows Parsed column.
Match Summary
The number and percent of records that were matched, the match type (either ACT![]() A high confidence match between two records. ACT matches result in a merge without any human review. or ASK
A high confidence match between two records. ACT matches result in a merge without any human review. or ASK![]() A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches), and how many did not match.
A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches), and how many did not match.
Note: The percentages may not equal 100 due to rounding.
Merge Summary
Details about all of the completed merges. If no merges occurred during the job, this section is empty.
Job Triggers Summary
Identifies how the job started and any subsequent jobs or emails that were triggered by this job.
Job Error Log
Warnings or errors that occurred while the job ran. For details see Job error log.
Some of the error messages that you might see in the Job Error Log will be similar to the blocking errors found in source subscription jobs because both use match configurations.
The following error can occur when the job encounters issues with Veeva-owned records:
A match between <VID> and <VID> has been rejected because neither entity is customer owned.
Veeva-owned records cannot be merged together. To resolve these errors, review the rules in the match configuration.
Exported file
A file containing a list of all the rejected pairs is exported after every data deduplication job completes.
The file lists all of the record pairs that matched based on the match configuration but were not merged or included in a suspect match task (because the records were previously rejected as matches). The file name follows this format:
<systemname>-<entitytype>-MATCH-ANALYSIS-<timestamp>-<job id>-REJECTED-PAIRS.csv

Suspect match considerations
DM
Any ASK![]() A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. match outcomes from the data deduplication job result in suspect match tasks in the Inbox.
A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. match outcomes from the data deduplication job result in suspect match tasks in the Inbox.
Task limit
To minimize the load and work produced for data stewards, a limit of 200 suspect match tasks can be created during each job.
If the number of tasks exceeds 200, a warning displays in the Job Error Log.
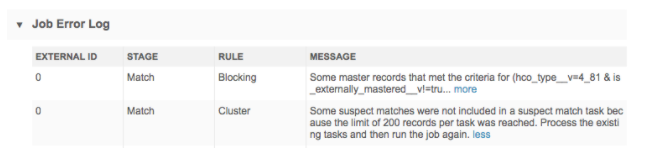
After the data steward team has reviewed the 200 suspect match tasks, run the job again until this warning no longer occurs.
Record limit for each task
To ensure that suspect match tasks can be easily actioned by data stewards, a limit of 20 records can be included in one task.
If the number of records in a task exceeds 20, a warning is logged in the Job Error Log. To resolve the warning, run the same job multiple times until this warning no longer occurs.
Considerations for pending matches
If two or more records are already in a pending suspect match task in the inbox, a new suspect match task containing exactly the same group of records will not be created by the new data deduplication job. This behavior can be overridden by selecting the Include in Matching: All previously processed records option in the Settings section.
Records not considered for matching
By default, some records will not be considered as potential matches again unless the content of the record changes.
To allow these records to be considered, select the specific Allow in Matching options in the Match Settings section.
| Records Not Considered by Default | Allow in Matching |
|---|---|
| Two or more records already in a pending suspect match task. A new suspect match task containing exactly the same group of records will not be created. |
Records in pending suspect match tasks |
| Records that have been previously unmerged | Previously unmerged records |
| Records that have previously been rejected in a suspect match task | Records in previously rejected suspect match tasks |
Managing the Inbox
To help data stewards manage their inbox after a data deduplication job completes, they can filter their inbox for suspect match tasks using the data_dedup__v source system.