Data deduplication
DM
Administrators and data managers can create data maintenance![]() User directed automated jobs that improve data quality by targeting specific data quality issues like sub-object inactivation and data deduplication detection. subscriptions to identify duplicate HCP and HCO records in their Network MDM instance.
User directed automated jobs that improve data quality by targeting specific data quality issues like sub-object inactivation and data deduplication detection. subscriptions to identify duplicate HCP and HCO records in their Network MDM instance.
Duplicate records can exist for the following reasons:
-
poor match rules
-
DCR processing errors
-
records are added without searching for existing records first
Use data deduplication jobs to compare specific records in your Network MDM instance against all other records in your instance.
This feature is enabled by default in your Network MDM instance.
Supported objects
-
Veeva objects only (HCPs, HCOs)
Custom objects or not supported.
Finding duplicate records
Similar to source subscriptions, data deduplication subscriptions use the following tools:
- Data groups - narrows the number of records being compared
- Match rules - determines if records are the same or not
Match logs contain a summary of the records that were merged or suspect matched during the job. Comparisons are done at the entity level. Existing merge rules are used for sub-objects when records are merged.
All previous unmerges, rejected suspect matches, and duplicates that have occurred in the instance are tracked and can be ignored from comparisons when you create a data deduplication job.
The jobs can be thoroughly tested before you commit to merging any records.
Address matching
The Data Deduplication feature finds duplications at the entity level (HCP/HCO), but addresses are also considered during the match process.
Review the different match and merge scenarios related to gray address during the data deduplication job.
Note: The match scenarios for local (gray) addresses on Veeva (orange) records is the same for third-party mastered (blue) records.
Considerations for data deduplication subscriptions
Before you create a subscription, review the following considerations.
Match types
Begin using data deduplication with ASK![]() A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches only.
A single incoming record matches multiple incoming or Network records without one clear "best" match. Ambiguous matches typically require human review. matches only.
After you have tested the job and are confident in your match rules, you can introduce ACT![]() A high confidence match between two records. ACT matches result in a merge without any human review. matches.
A high confidence match between two records. ACT matches result in a merge without any human review. matches.
Job size
Jobs can take some time to run, so prioritize your data and work with small, logical sets of data for each data deduplication job.
Supported records
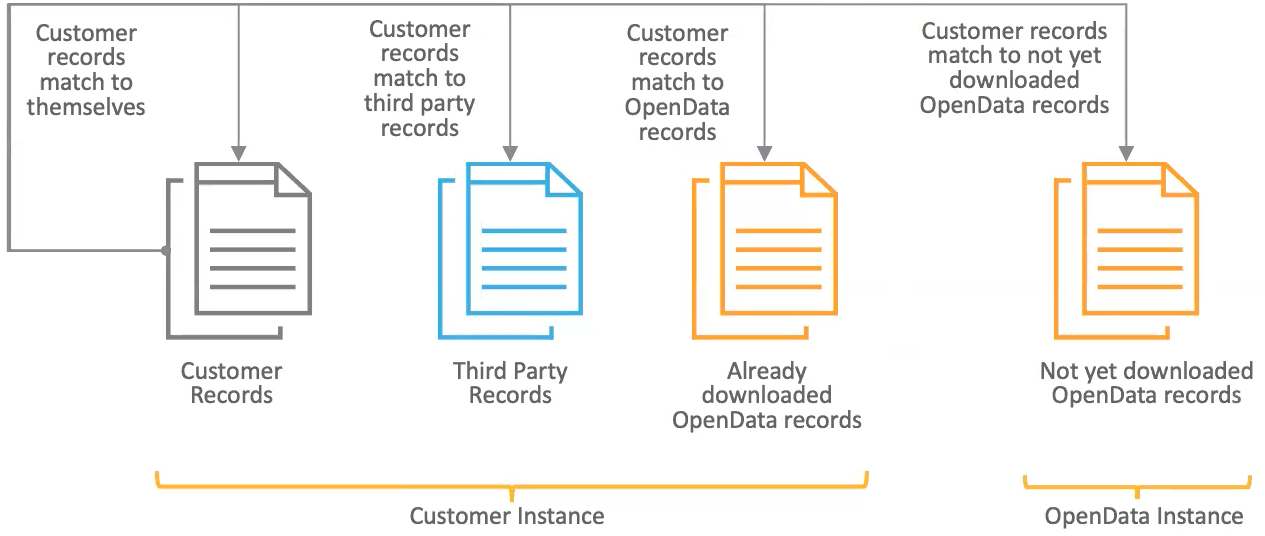
Only active and valid customer-owned HCP and HCO records from the specified Network IDs are compared.
These records are compared against all of the records in the instance, including Veeva OpenData records, third party owned records and other local records.
Valid records for a country where match rules are not defined are skipped because the data deduplication process cannot match those records.
Sub-objects
Active and inactive sub-objects are considered in the match comparisons to help identify duplicate entities in your Network MDM instance.
Excluded records
The following record types are excluded from the comparison:
-
invalid
-
under review
 A record that has not yet been validated by a data steward.
A record that has not yet been validated by a data steward. -
externally managed (Veeva OpenData or third party)
Job limits
-
Individual Task Record Limit - Each suspect match task is limited to 20 records. If the limit is exceeded, the job completes with errors.
-
Number of Suspect Match Task - Each job can produce a maximum of 200 suspect match tasks. If the limit is exceeded, the job completes with errors.
-
Number of matches - Each job can produce a maximum of 20 million match pairs. If the limit is exceeded, the job fails.
These restrictions exist to ensure your data stewards are able to keep up with tasks created by data deduplication jobs and aren't overwhelmed by the contents. The limits apply to each job so as tasks are reviewed and updated, new potential matches may be created when the job runs again in the future.
Match and Download from Veeva OpenData
During the job, customer owned-records are compared against all records that exist in your Network MDM instance.
You can enable the Match & Download from OpenData option in the subscription to also match against records in the OpenData instances.
OpenData records that match will be downloaded to your Network MDM instance during the job.
Match and Download from OpenData limits
A maximum of 5000 records can be matched and downloaded from OpenData in each source subscription or data deduplication job. If the job tries to download more than 5000 records, the job will fail.This limitation applies only to customers that purchase OpenData per record for a country. It does not apply to customers that purchase all records for a country.