Data transformation queries
Custom table output
Administrators and Data Managers can now create custom tables from transformation query output. Previously, transformation query output was available only as .csv files. Saving the query output to a custom table enables you to automatically load data into custom tables from source and target subscriptions.
This feature is enabled by default in your network instance
Benefits
Using the custom table output option enables you to do, for example, the following activities:
-
Create snapshots of current data in Network.
This could be a snapshot of data for a data model object, a reporting table, a lookup table, or another custom table.
-
Create a source subscription that loads data from a source file into a custom table.
-
Prevent intermediate files in target subscription export packages.
Configure transformation query output as custom tables
Transformation query configurations now contain a Query Output section to support the option for creating custom tables.
![]()
To save the query output as a custom table, define the following settings:
-
In the Query Output section, select Custom Table.
Tip: You can also save the output as both a custom table and a .csv file or .csv file only.
-
Define a Table Name and Table Description. The table name will automatically be appended with the __ct suffix.
-
Choose the folder where the table will be saved. If you have folders created in the Shared Folders category in the SQL Query Editor, they will display in this list.
Transformation queries cannot be saved to personal folders (My Custom Tables) because the data is loaded through subscriptions, which are not applied to users.
-
Choose Table Name Options.
-
Static table name - The table name is always the same, so it means any existing custom table with the same name is replaced each time the query runs. For example: hco_table__ct
-
Add timestamp to table name - Append a timestamp to the table name. For example: hco_table_20221102t045341z__ct.
-
Add job ID to table name - Append the subscription job ID to the table name. For example: hco_table_15953__ct
-
Subscription configuration updates
Source and target subscription configurations are updated to identify the type of output from the query.
Transformation Queries section
The Query Output column now lists the .csv file and/or custom table that will be created when the job runs. If the file name is truncated, hover over the column to see a tooltip with the complete file names.
![]()
Note: If the custom table name appends a timestamp or job ID, a placeholder is added to the filename until the job runs.
Data flow view
The Apply Transformation Queries stage of the Data Flow View displays all of the output types for the query.
![]()
Job details page
The Transformation Queries section displays the files and custom tables created by the job.
If the file name is truncated, hover over it to see the full file name in a tooltip.
![]()
The following examples highlight the key use cases for loading transformed data into custom tables.
Example 1 - Create snapshots of current data
Use a target subscription to export an object or a table so you can take a snapshot of the current data. The transformation query reads from the file export or table and persists the query output as a custom table.
For example, you might want to take snapshots of hierarchies so you can track any HCOs or HCPs that are dropped and added each quarter because it could affect compensation processes. You can do this by taking snapshots of Network's flattened hierarchy table using a transformation query.
Process
-
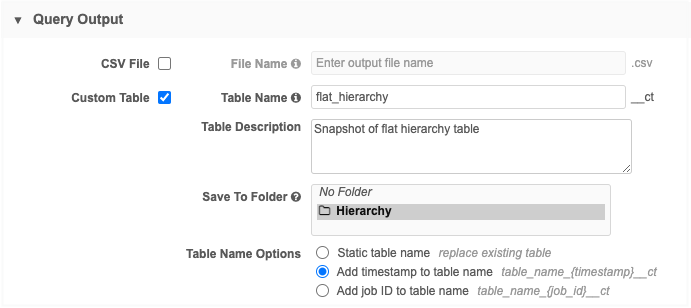
Create a transformation query that queries the flat_hiearchy reporting table. Configure the transformation query to create a custom table which includes a timestamp in the table name.
-
Apply the query to a target subscription.
-
Run the target subscription monthly or quarterly to create a custom table so you can compare data.
Create the transformation query
Create an outbound transformation query so you can apply it to a target subscription.
Key settings:
-
Query Output section- Define the following settings:
-
Choose Custom Table.
-
Assign a name and description.
-
Save the custom table to a shared folder in the SQL Query Editor. If there are no folders in the list, it is saved to No Folder (top level of the Shared Folder).
-
In the Table Name Options, choose Add timestamp to table name. This ensures that you have the date of the snapshot as part of the filename.
-
-
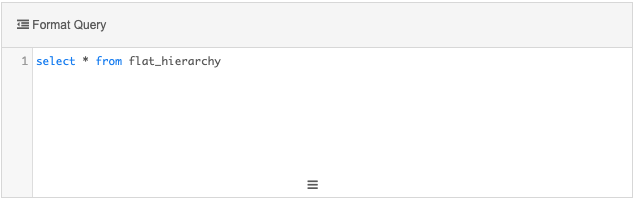
Transformation Query section - Add a simple query to return all of the data from the flat_hiearchy table.
select * from flat_hierarchy
Create a target subscription
Create a new target subscription and configure it so that no files are exported; only the custom table is created.
Key details:
-
General Export Options section - Accept the default setting values in this section.
-
File & Field Selection section - Choose the Export None export option. This sets all of the objects to Do Not Export.
-
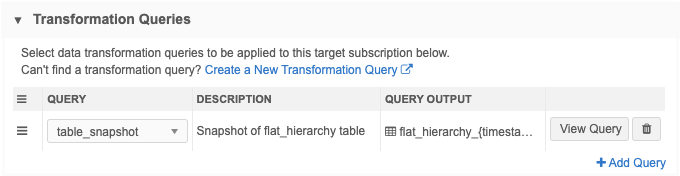
Transformation Queries section - Add the transformation query to the source subscription.
-
Job Schedule & Triggers section - Schedule the job to capture snapshots of the flat_hierarchy reporting table. For example, schedule it to run quarterly or monthly.
-
Job Details - After the job runs, the Transformation Queries section on the Job Details page displays the custom table and number of records that were processed.

Click View Query to open a dialog that contains the original transformation query.
Review the custom table in the SQL Query Editor
The Shared Tables section contains the custom table that was created by the job.
Expand the table to see the metadata; the subscription name and Job ID that created the table and the transformation query name.
![]()
You can add the table to a query to return the results from the flat_hierachy table for this date.
To review the original query, hover over the custom table and click the Copy Source Query to Clipboard icon. Paste the query to the SQL Query Editor box.
![]()
Result
Each time the target subscription runs, it will create a custom table with a timestamp. Use the custom tables to compare the data between different time periods.
Example 2 - Prevent intermediate files in subscription packages
Some target subscriptions might include multiple transformation queries that run in sequence. For example, the first query runs and produces the results that are read by a second query. Before this Network release, each time a query ran, a file was created and included in the export file package. This means that some files are exported unnecessarily.
To prevent these files from being exported to downstream systems, you can create custom tables as the output of any intermediary queries. This ensures that the data remains in Network as a custom table and unnecessary files are not exported.
Note: If you have existing transformation queries that are sequenced, the query output will remain a .csv file in the query configuration.
Process
-
Create a transformation query that is configured to create a custom table.
-
Create another transformation query that will read the results of the first transformation query. Configure the query output as a .csv file that will be exported.
-
Create a target subscription that will export the .csv file created by the second transformation query.
Create transformation queries
In this example, we'll create two transformation queries to export HCP data. The output of the first query will be read by the second query.
Query 1
-
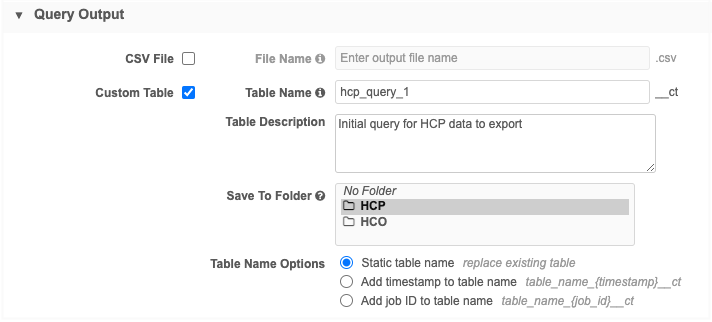
Create an outbound query and define the output as a Custom Table.
-
Choose the Static table name option so the table is replaced each time the query runs.
-
Add the query that will generate the results that will be read by Query 2.
Example query
This query will return all HCPs that are doctors.
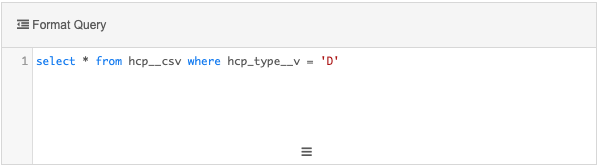
Query 2
This is the query that will return the results that we want to export.
-
Create an outbound query and choose CSV File as the output. Provide a file name.
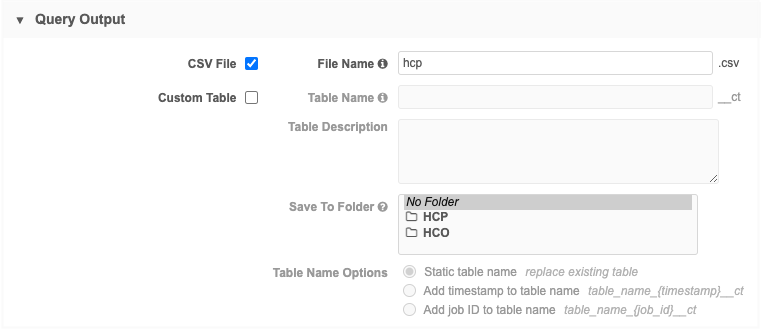
-
Add the query that will read the results from Query 1.
Example query
This query reads from the custom table output of Query 1 to return all HCPs that are doctors and whose focus area is pediatrics.
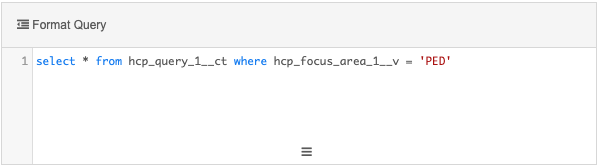
Create a target subscription
Create a subscription and configure it so only the HCP object and fields are exported.
Key details:
-
General Export Options - Configure the settings as you would typically do for an HCP export.
-
File & Field Selection - Choose the Export None export option to set all objects to Do Not Export. Then, choose Select Which Objects and Fields to Export and set the Health Care Professional object to Export All Fields or Export Some Fields depending on your data.
-
Transformation Queries - Add both transformation queries to the target subscription.
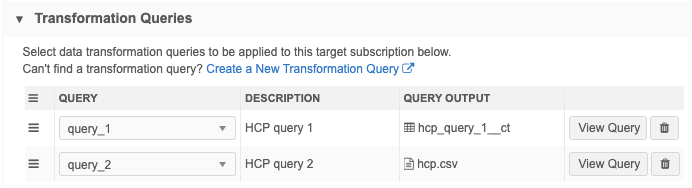
-
Job Details - After the job runs, both queries are listed in the Transformation Queries section on the Job Details page.

-
Data flow view - The Generate Files section confirms that the only file that will be exported is the hcp.csv output file from the second query.
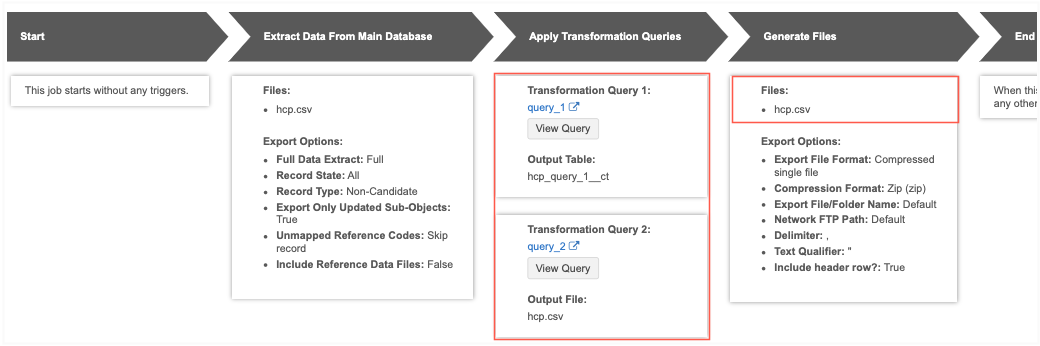
Review the custom table in the SQL Query Editor
The custom table created from the first query is saved to the Shared Custom Tables section.
Expand the table name to review the metadata.
This was created as a static table, so it will be replaced each time the target subscription runs.
![]()
Result
Using a custom table as the output of Query 1 ensures that the only file that is included in the export is the data intended for downstream systems.
Example 3 - Loading data directly from source subscriptions
Previously, custom tables could only be created manually, either by uploading a file or by creating a table from report results in the SQL Query Editor. Now, you can create custom tables automatically by loading data through subscription jobs.
In this example, we will configure a source subscription to process a file on our FTP server. The data won't be loaded into the HCP object; it will be loaded into a custom table so we can report on the data to review the potential updates.
Source subscription process
Transformation queries are the first thing that is run in a source subscription.
This is important to know for the following reasons:
-
The transformation query will always be run, even if the Apply Updates & Merges setting is disabled or if the job fails in a later stage. This means the data in the custom table will be updated or replaced.
-
Since the transformation query runs first in the job, any updates potentially made by the source subscription are not applied yet when the custom table is created. This means that any data that you report on using the custom table does not contain the updates that are applied in later stages by the source subscription.
For example, if you use a source subscription to take a snapshot of data
Create a transformation query
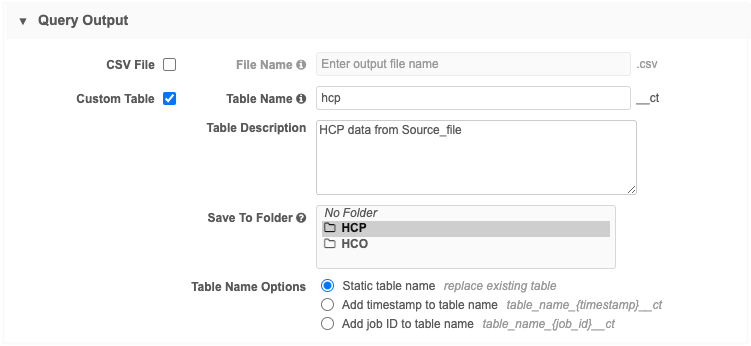
Create an inbound query to load data from a source file directly to a custom table.
Key details:
-
Query Output - Define the following settings:
-
Choose Custom Table.
-
Assign a name and description.
-
Save the custom table to a shared folder in the SQL Query Editor. If there are no folders in the list, it is saved to No Folder (top level of the Shared Folder).
-
In the Table Name Options, you can choose any naming convention depending on your desired outcome. For this example, we will choose Static table name so the table will be replaced each time the source subscription runs.
-
-
Transformation Query section - Add the query.
Example
select * from source_file__csv
Create a source subscription
Using Classic Mode, configure a source subscription to load the data into a custom table.
Key details:
-
Settings section - Accept the default values. The source subscription will not be processing the data, it will be loading the data into the custom table only.
-
Source files section - Files that are used by the transformation query must be defined here. Add the source file that contains the data that the query will read from.
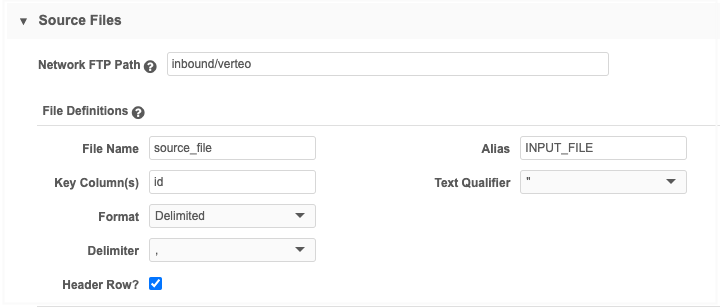
Note: The source subscription in this example does not process any data to be loaded into data model objects, so Field Normalizations, Model Map definitions, Network Expression Rules, and Match Configuration are not required.
-
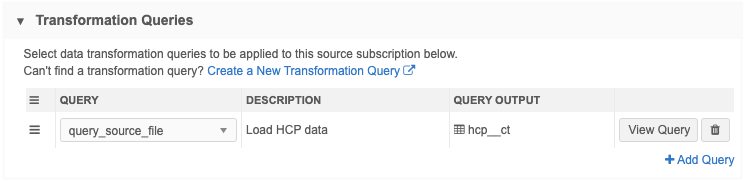
Transformation queries section - Add the transformation query to the source subscription.
-
Job Details - After the job runs, the Files Loaded Summary and Data Load Summary sections identify the files that were loaded and the rows of data that were read and parsed.
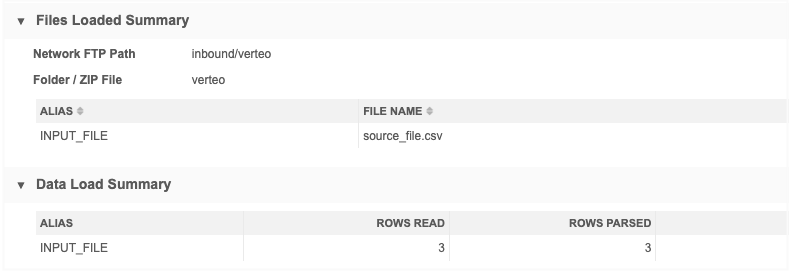
Note: There are no counts for objects listed in the Processed Data Summary, Match Summary, and Job Result Summary sections.
Transformation Queries section - This section identifies the query that ran, the custom table name for the output file and the number of records included in the table.

Review the custom table in the SQL Query Editor
The custom table created by the source subscription is available in the Shared Custom Tables section.
-
Expand the table name to review the metadata.
-
Add the table to a query to review the data that was loaded.
![]()
Result
There are three HCP records in the custom table.
Upserting or appending delta uploads
The scenario above is for full data loads. Because we created a custom table with a static table name, the table will be replaced each time the subscription runs. You might want to update a custom table on scheduled basis. To upsert or append a delta upload to the existing table, we can write the logic into a transformation query.
We can create a transformation query for delta uploads using the same custom table name (hcp__ct) as we did for the previous query. The custom table will be replaced, but the transformation query that we create will union the two data sets from the incoming delta file and the existing custom table.
Upsert example
To add new records and update changed records in the existing custom table, you can upsert a delta file. Create a transformation query will union the incoming records from the delta file with the existing records in the custom table. Use a LEFT JOIN and a WHERE clause to remove any existing records in the custom table that match on the same ID in the incoming delta file.
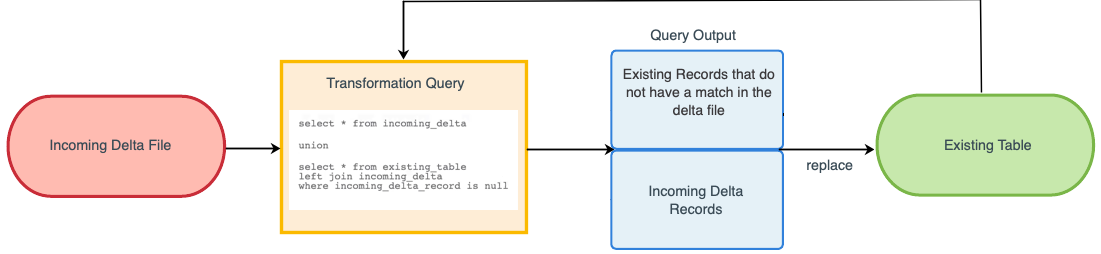
Example query
SELECT
id,
first_name,
last_name,
specialty
FROM
source_file_delta__csv
UNION
SELECT
hcp__ct.id,
hcp__ct.first_name,
hcp__ct.last_name,
hcp__ct.specialty
FROM
hcp__ct LEFT JOIN source_file_delta__csv
ON hcp__ct.id = source_file_delta__csv.id
WHERE
source_file_delta__csv.id IS NULL
Append example
To append a delta file to a custom table, the transformation query should simply union the incoming records from the delta file with the existing records in the custom table. An append means that all records from the incoming file are added to the existing custom table. Ensure that the incoming delta file includes only new records and no changes to existing records; otherwise, the custom table will have duplicated records.
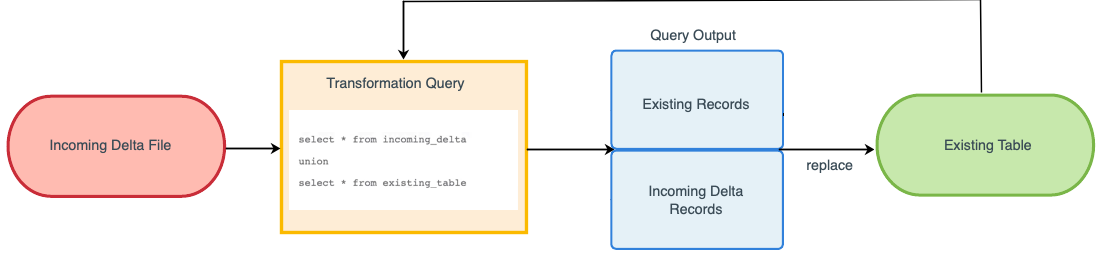
Example query
SELECT
id,
first_name,
last_name,
specialty
FROM
source_file_delta__csv
UNION
SELECT
id,
first_name,
last_name,
specialty
FROM
hcp__ct
Managing configurations
Transformation queries can be exported to a target environment.
If you export queries, Network will import the custom table into the same shared folder in the target environment if it is found. If the shared folder does not exist, the custom folder is saved to the root level of the Shared Folder.
Dependencies
When you export transformation queries, source subscriptions and target subscriptions are not automatically added to the export package. They must be manually added.