Data maintenance subscriptions
Data deduplication
Data deduplication subscriptions try to match existing locally managed records with other records in your Network instance. Now, Administrators can configure the subscription to look for duplicates with OpenData records that have not yet been downloaded to your Network instance.

If a strong (ACT) match is found to an OpenData record during the job, the record is downloaded and the local record is merged into it.
This feature is available by default in your Network instance. Administrators can enable the setting in the data deduplication subscription.
Enable matching to OpenData instances
To enable the setting:
-
Create or open a Data Deduplication subscription (System Interfaces > Data Maintenance Subscriptions).
-
In the Match Settings section, click the Match & Download from OpenData setting.
When this setting is enabled, the job will try to match the existing locally managed record to a record in the related OpenData instance.
If strong (ACT) matches are found, the job will download the record from OpenData and the locally managed record will be merged.
Tip: To ensure that the highest ranked match is found, enable the Consider records in OpenData Instances setting (General Settings). The match process will continue looking for a superior match in the OpenData instance even if a match has already been found in your Network instance. For more information, see Match & Download from OpenData in the Veeva Network Online Help.
Match settings
In addition to adding the Match & Download from OpenData setting in this release, the Allow in Matching setting has been extracted into individual options to give you more control over the records that can be matched during the job. Previously, this was one setting called Previously Unmerged/Pending & Rejected Suspect Match Records.

Select all options that you want the job to consider for potential matches.
-
Records in pending suspect match tasks
-
Records in previously suspected match task
-
Previously unmerged records
If an existing subscription had this setting enabled, then all the new Allow in Matching options are selected.
Job limits
Existing limits on Data Deduplication jobs and for downloading records from OpenData apply when the Match and Download from OpenData setting is enabled.
Existing Data Deduplication job limits
-
Suspect match task - record limit - Each task that is created by the job is limited to 20 records. If the limit is exceeded, the job completes with errors.
-
Suspect match task - number of tasks - Each job can produce a maximum of 200 suspect match tasks. If the limit is exceeded, the job completes with errors.
-
Number of matches - Each job can produce a maximum of 20 million matches. If the limit is exceeded, the job fails.
Existing Match and Download from OpenData limits
-
Downloaded records limit - A maximum of 5000 records can be matched and downloaded from OpenData in each job. If the job tries to download more than 5000 records, the job will fail.
This limitation applies to customers that purchase OpenData per record for a country. It applies when records are matched and downloaded from OpenData in source subscriptions and data deduplication subscriptions.
It does not apply to customers that purchase all records for a country.
Reviewing the job outcome
Use the existing Job Action options to review the job outcome before downloading and merging records.
To pause the job and review the outcome, choose Review before Merge.
When this setting is on, the job will stop before any changes are committed. Export the match logs so you can review the potential merges and records that will be downloaded from OpenData.
Match log updates
The Match+Data-Group-Analysis log for Data Deduplication jobs are updated to indicate when matches are found in OpenData instances.
-
Mode column - The OpenData Deduplication value is added.
-
Match Id column - The OpenData instance ID is added to the beginning of the column value. (This is the same behavior for source subscription logs).

Job validation rules
Job validation rules can now be applied to selected data maintenance subscriptions to ensure that critical updates occur as expected. Use the rules to check if a job is unintentionally inactivating or deleting a lot of records. This is particularly helpful if you have automated the process for unsubscribing or soft-deleting records.
Validation rules can be applied to the following data maintenance subscriptions:
-
Delete Locally Managed HCP/HCO
-
Delete Custom Object Records
-
Unsubscribe OpenData Records
Tip: Unsubscribe from Third Party Records jobs already support job validation rules because these jobs are run using NEX rules in source subscriptions.
This enhancement is on by default in your Network instance.
Job validation rules
A set of default validation rules are provided for Veeva standard objects (System Interfaces > Job Validation Rules). These rules are on by default.
For data maintenance subscriptions, the applicable default job validation rules are the rules that check for records being deleted. For example, if job validation rules are applied, the HCPIsDeleted rule will fail a Delete Locally Managed HCP/HCO job if the job tries to delete 100 or more HCP records.
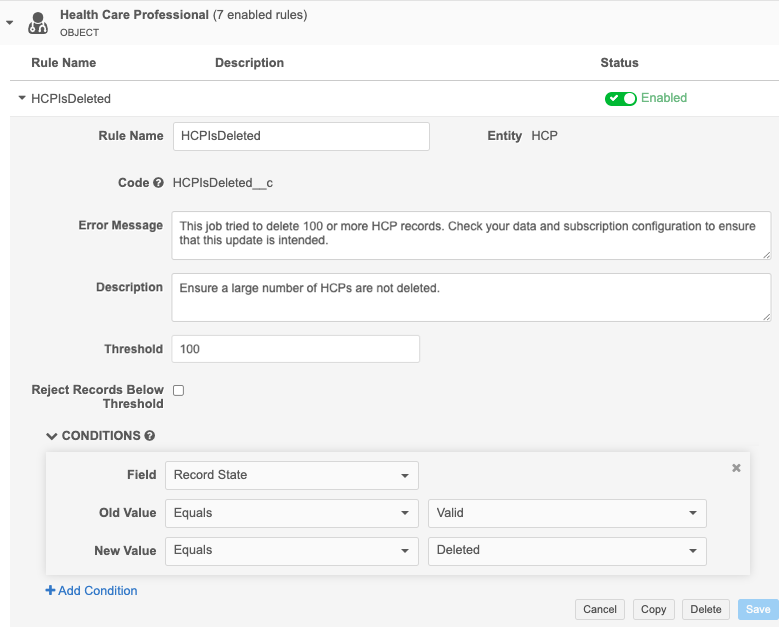
Create rules
Rules can be added for Veeva objects and for custom objects that are enabled in your Network instance.
Apply job validation rules
The supported data maintenance subscriptions contain a new setting called Apply All Enabled Data Validation Rules. Select the setting to apply job validation rules to the job.

Failed rules
If a job validation rule threshold is met, the data maintenance job fails and no changes are made to the data. Open the Job Details page to see an error and the rule name in the Job Error Log.

Logs
When job validation rules are applied to data maintenance subscriptions, log files are created. View the log files in the outbound > job_validation_rules directory in File Explorer. A .zip file is created for each job.
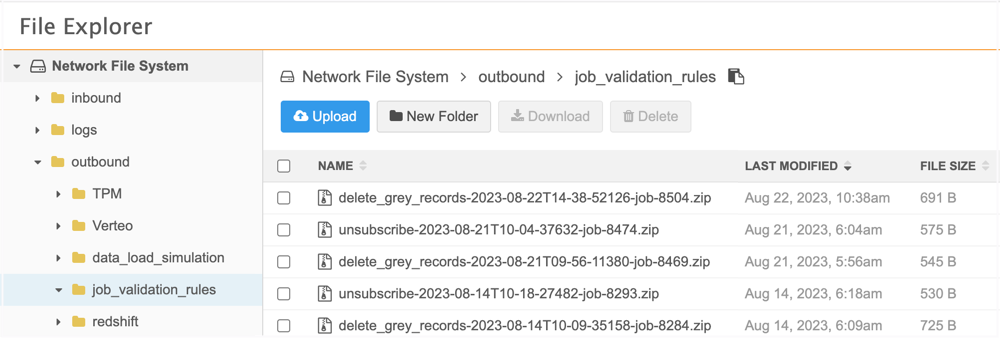
Open the .zip file to review the .csv file for the job.
The .zip file and .csv file have the following naming convention: <subscription_name>-<timestamp>-job-<job ID>.
Example job log
In the file, you can review the changes that the job tried to make and the rule that was used to detect the change.
