Defining match rules
DM
Match rules determine how matching is performed between incoming records and existing records within the defined data groups.
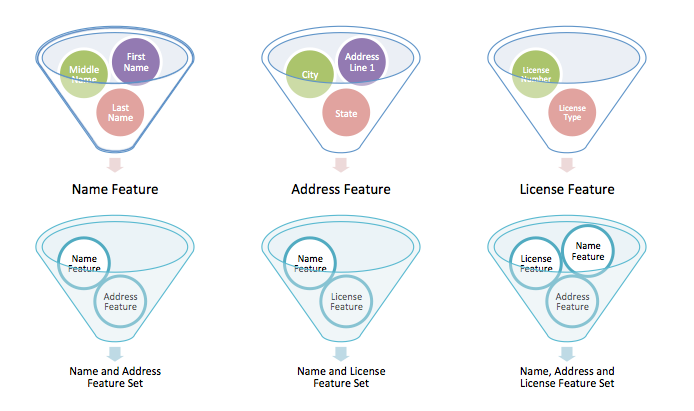
Individual data elements such as first, middle, and last name are the key elements for final match rules, and are used to create features.
Features
Features are combined in one or many ways to create feature sets. Finally, each feature set is given a confidence level that dictates what Network MDM will do for any record pair that meets the rules for that feature set.
Each classifier begins with the <ruleClassifier> tag. The closing tag, </ruleClassifier>, concludes the entire classifier.
See Defining features for more information.
Feature sets
Feature sets consist of feature groupings that are ultimately assigned confidence levels to determine how Network MDM treats record pairs that meet the rules for the feature set.
Feature sets are categorized by rules that should result in one of the following:
-
ACT - Records are automatically merged.
-
ASK - A suspect match task.
See Feature sets for more information.
Confidence levels
Within the match rules, feature sets define comparison methods for selected features and are configured with a confidence level, or threshold. The confidence level dictates how Network MDM deals with the corresponding matched data pairs.
Three types of actions determine how Network MDM responds:
- ACT actions tell Network MDM to automatically merge pairs that are considered a strong match.
- ASK actions tell Network MDM to send the pairs that are a possible match to customer data stewards for review. The reviewer can choose to merge the records or keep them separate. Keeping them separate results in a new customer-owned record.
- ADD actions tell Network MDM to automatically create a new customer-owned record for an incoming record that is not considered a match to any Network MDM or customer-owned record in the customer instance.
ACT and ASK confidence levels are defined in the match rules; ADD actions are not, as they are implied upon failure of the other confidence levels.
Set levels
-
ACT matches - Set at 0.9 so any feature set with a confidence level of 0.9 or higher will automatically merge
-
ASK matches - Set at 0.8. so any feature set with a confidence level of 0.8 or higher but less than 0.9 will be sent to a data steward for review.
Note: ASK matches for Veeva OpenData records that have not been downloaded do not result in suspect matches; Suspect matches only include records that are already in an instance. VIDs for either match scenario (whether the record is downloaded or not) display in the match logs.
Confidence values in features
Within a feature set, features referenced in that set each of their own confidence values that factor into the final ACT or ASK outcomes. A match outcome is determined by the highest feature set where the matching records passed all features within the set.
For example, the following feature set contains the these features: names are identical and licenses match.
<featureSet> <name>names are identical and licenses match</name> <confidence>0.94</confidence> <feature>names are identical</feature> <feature>licenses match</feature> </featureSet>
Each feature in the feature set has its own confidence threshold; for example, .85 for names are identical and .9 for licenses match. The features within this feature set, and the confidence value of the feature set itself must be unique.
Default match rules
Network MDM includes default match rules![]() A definition that determines which fields in a record are a possible match and when a record comparison is considered a suspect match. See features and feature sets. that are tuned to align with the characteristics of data in a particular country. They are tailored by country to consider differences between Latin and Chinese character sets.
A definition that determines which fields in a record are a possible match and when a record comparison is considered a suspect match. See features and feature sets. that are tuned to align with the characteristics of data in a particular country. They are tailored by country to consider differences between Latin and Chinese character sets.
-
Ad Hoc Match Configuration – Used only for ad hoc matching. Supported for HCPs and HCOs only.
-
Add Request Match Configuration – Used for all users and systems submitting add requests to a Network MDM instance.
-
Match Default Configuration – Used by subscriptions you create in your Network MDM instance and by Network MDM internal subscriptions (change_request and merge_request).
Note: The change request (
change_request__v) and merge request (merge_request__v) subscriptions are internal, hidden subscriptions used by Network MDM when processing all add, change, or merge requests done through the UI or API calls. API calls are used by external systems like CRM.By default, all source subscriptions perform key matching first, and then use match rules for any incoming data. Match rules are defined per country and applied accordingly to the primary country of each incoming record.
Overriding default match rules
The match rules can be changed to benefit your specific data. If Network MDM updates the default match rules, your changes are not overridden.
Each match configuration shows if you are using the default rules or if they have been overridden.
