Defining features
DM
Features determine how individual field pairs are matched and can be uniquely assigned a match algorithm, match filter, confidence level, and null matching treatment.
Multiple features make up a feature set.
Define features
To add a feature:
- Click the Match Rules tab to view the current match rules configuration.
- To the right of the match rules header, click the Entity drop-down list and select HCP or HCO to work with the match rules for that entity type.
- Click the Add Feature at the bottom of the list (or the + at the top right of the list) to add more features.
- Type a descriptive name for the new feature.
- In the Fields list, select the fields to include in the feature. As you type, auto-complete options appear.
To match on the parent HCO fields, select Compare fields from Parent HCO records. For example, the parent HCOs of John Smith can be compared during loading. This provides more flexibility for matching records.
- In the Apply Filters section, click +Add Filter to include or exclude values from specific fields in their match rules. For example, a license match rule can exclude DEA type licenses, or an HCO match rule can include a specific list of HCO types.
- Expand the Field list and select a data model field.
- Expand the Value list and select the specific values for the condition.
- In the Function list, choose either Include or Exclude.
- To create additional filters, click +Add Filter again and configure the filter.
Filters are supported only for the Direct field comparison method. Filters created for any other comparison method are ignored.
For more information, see Conditional matching.
-
In the Comparison method list, select the comparison method to use for the feature.
-
Concatenate fields - All selected fields are combined into one and then match comparisons are done.
This addresses the issue where source data stores name components in different fields than existing records. The NGram algorithm is a good choice when working with Latin strings.
-
Direct field - As the name indicates, all selected fields are compared to the identical field name in the instance.
-
Sets of fields - Network has many field sets. Choose this option to match data in these fields.
Each field is compared to the other across the full set of fields. If at least one of the pairs compared comparison results are true, the outcome is "SUPPORT".
Note: Field sets are not editable. If you choose all Email fields (
email_1__vtoemail_10__v) and also include a custom field that contains email addresses, the set matching feature will only look at the 'standard' email fields. The custom field is ignored.
Hover over the Help ? icon to see examples.

-
-
In the Null value options list, select the method of treatment to use for null values. This can be a key impact for match outcomes.
For details, see Configuring null matching in features.
-
In the Success criteria section, select an algorithm to use for the matching process. You can click Add Algorithm at the bottom of this section to add more.
For more information about the available algorithms, see Leveraging algorithms for comparison.
- Click the Enabled checkbox to include this feature in the matching process.
- Type descriptive comments for the feature and click Done to add the new feature.
Example feature
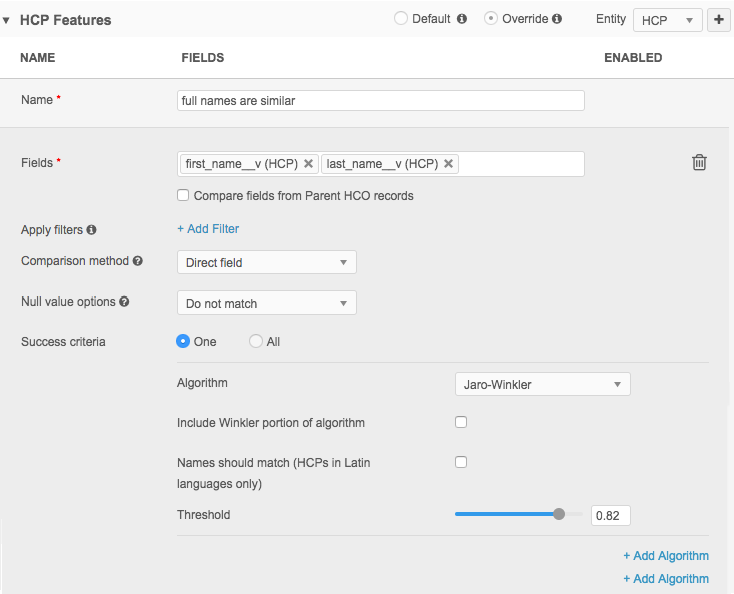
Note: If a feature does not appear in any feature set defined in the previous section, an information icon appears next to the left of the feature name.
Applying filtered match rules to incoming records
Filters can be applied to individual features or all features for the object in the match configuration.
When filters are applied, the rules can consider incoming records even if they are missing the field value of the filter.
To define the behavior:
-
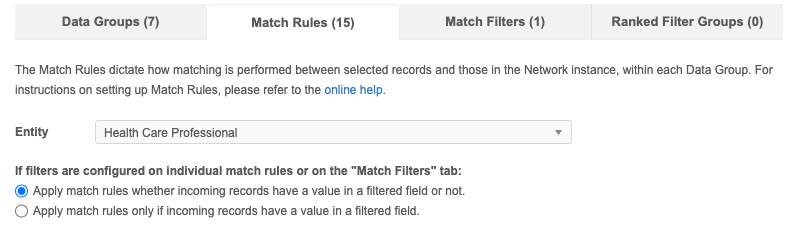
Click the Match Rules tab.
-
Select one of the options:
-
Apply match rules whether incoming records have a value in the filtered field or not.
-
Apply match rules only if incoming records have a value in a filtered field.
-
Supported match rules
-
Individual match rules (Match Rules tab)
-
Subscription-level match rules (Match Filters tab)
Supported match filters
This is supported when the filter function is Include.
Exclude functions require the records to have the specified field and value.
Create features in Advanced mode
Features can be defined using XML.
For details, see Defining match configurations in Advanced mode.