Exporting US compliance data
DM
Use the US Compliance target subscription to export the raw data from various sources to use in federal and state transparency reporting.
This subscription gives you access to raw NPI, SLN, and DEA data elements. For example, you can use the subscription to report the NPI taxonomy codes (specialty codes) and the name, address and telephone attributes of an entity as tracked by NPI and required by the Sunshine Act. After the subscription runs and exports the data to your data warehouse, aggregate spend, or other data processing platform, you can match the raw data to the transactional data for reporting.
You can export the following compliance data using the US Compliance Target Subscription:
- Health Care Professionals - NPI, DEA, Massachussetts (MA) CRI, and SLN data
- Health Care Organizations - NPI, DEA, and CMS Teaching Hospital data
Compliance data can be viewed on US record profiles in the Transparency Reporting preview box. For details, see Viewing compliance data.
About the data
Veeva OpenData prepares the raw data files. Compliance data is stored on a separate server because of the high volume of raw data. Because it is not available in customer or OpenData master instances, the data is not accessible for Network search, reporting, or regular target subscriptions.
When you run a US Compliance subscription job, the US data in your Network instance is matched against the raw data. Files are generated for each source that you defined in the subscription settings.
There are two types of files created for each source:
-
Found files - Contains records that matched data in the raw source (for example, SLN_hcp_found.csv).
Use this file for transparency reporting. Most of the column names are from the raw source file. Any columns that are not from the raw source will have column names that end in __v.
-
Not found files - Contains records where no data was found in the raw source (for example, SLN_hcp_not_found.csv).
This file cannot be used for transparency reporting because it contains records that are missing compliance data. Records might be incomplete or incorrect so they're missing the fields that are used for matching the data.
Update frequency
Compliance data is updated weekly by Veeva OpenData.
Run a compliance subscription
The target subscription is preconfigured, so no setup is required. It will access the server containing the source data and will try to match it to the US data in your Network instance. Click Start Job to immediately run the subscription to export all source data, or choose specific source data to export for HCPs and HCOs.
-
In the Admin console, click System Interfaces > US Compliance Target Subscription.
-
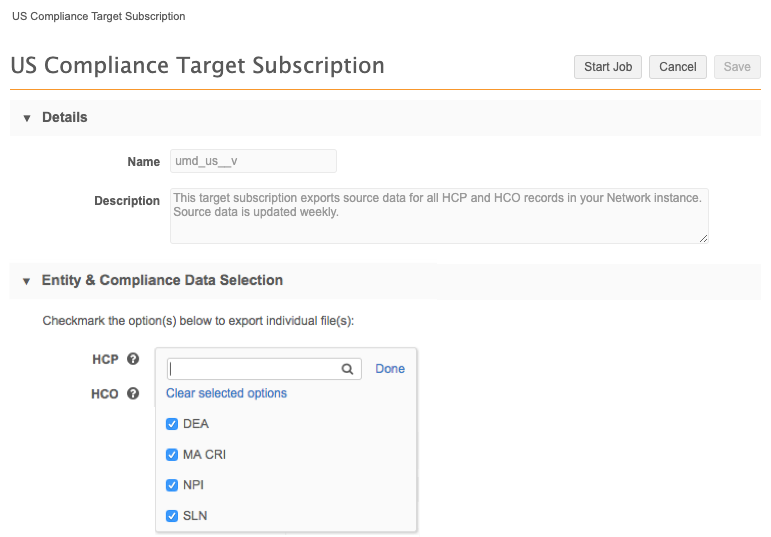
In the Entity & Compliance Data Selection section, expand the HCP and HCO lists and select the source data that you want to export.
Note: New Network instances have all available compliance data for HCPs and HCOs selected by default.
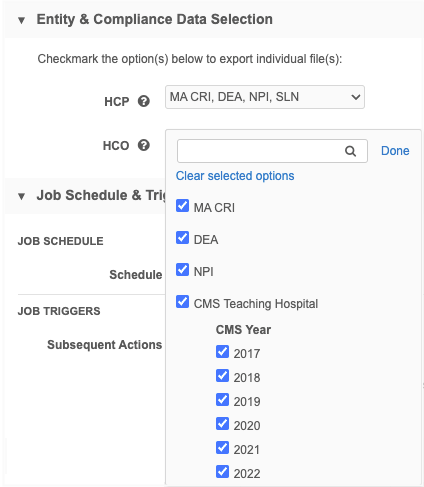
CMS Teaching Hospital data
The CMS Teaching Hospital option for HCOs enables you to select available years.
Select CMS Teaching Hospital to export data for all years or select individual years. If individual years are selected, the CMS Teaching Hospital option displays as partially selected.
Tip: Selecting the CMS Teaching Hospital option also ensures that data for a new year is automatically exported when it becomes available.
-
In the Job Trigger Configuration section, define the schedule for the job and any subsequent actions that will start when this job finishes.
- Job Schedule - Run the subscription manually or on a scheduled basis. If you select Manual, the subscription only runs when you click Start Job.
-
Job Triggers - Trigger other actions to start after a job runs.
Available triggers:
- Send email - Specify users that should be notified for successful and unsuccessful outcomes. For example, send an email to users so they will know if a job fails so they can investigate, or when the job completes so they can retrieve the source files from the FTP server.
- Start a job - Start a subsequent job when this job successfully completes.
For more information, see Subscription job triggers.
- Save your changes.
- Click Start Job to run the subscription or wait until it runs at the next scheduled time.
Exported source files
After the subscription job runs, individual files containing each set of data will be exported in a compressed (.zip) file and placed on your Network FTP server in the following folder:
/outbound/US_Compliance_Target_Subscription
The following files will be exported to the server:
-
found files - Data was found in the raw source for the record.
-
not_found files - No data was found in the raw source for the record.
- manifest.csv file - A system file that contains the record counts for each file.
The exported files will look similar to this example for MA CRI data:

Alternate keys
If your Network instance has alternate key type custom fields, they are exported when a record is exported in any of the various files. The alternate keys display in the file immediately after the Veeva Network ID (VID) column and before the compliance data.
Matching data in the source files
When the US Compliance target subscription runs, Network matches the US data in your Network instance with the data in the raw source file. Specific fields are used for matching data for each source. Some records are immediately excluded from the job.
Excluded records
Records are immediately excluded from the US Compliance job based on the values for the following fields:
- Primary county (
primary_country__v) – Any HCP or HCO record where the country is not the United States is excluded. - Record State - Any record (HCP, HCO, or license) where the state is Deleted or Invalid is excluded.
These records are not considered during the job and are not included in the exported files for any source.
Match criteria for data sources
For any records that are not immediately excluded based on primary country and record state, specific fields are used to match US records with the source data. If your US data matches the data in the raw source file, the record is added to the "found" file for that source. If data is not found in the raw source, the record is added to the "not found" file.
The fields that are used to match the data can be different depending on the entity owner of the record (either Veeva or local). To understand how records are matched for each source, review the following sections.
Records are added to the npi_<entity>_found.csv file if your US data matches the data in the raw source using the following fields:
Veeva records
- HCP -
vid__v - HCO -
vid__v
Local records
-
HCP -
npi_num__v, andfirst_name__v, andlast_name__vIf a match is not found using this combination of fields, the match criteria uses
npi_num__vandlast_name__v. - HCO -
npi_num__v
Records that are not matched to the source data using these fields are added to the npi_<entity>_not_found.csv file.
Excluded records
Besides being excluded for primary country and record state, HCP records can be excluded for the SLN source based on the following field values:
- License type (
type__v) - Must be State. If this field value is not State, HCP licenses are excluded. - License state (
record_state__v) - Cannot be Deleted or Invalid. If the license state is Deleted or Invalid, HCP licenses are excluded.
Match criteria
Records are added to the sln_hcp_found.csv file if your US data matches the data in the raw source using the following fields.
Veeva record
The fields that are used for matching are based on the owner of the license.
- License owner: Veeva -
vid__vandlicense_number__vandlicense_degree__vandtype_value__v -
License owner: Local -
license_number__vandlicense_degree__vandtype_value__vandfirst_name__vandlast_name__v.- If a match is not found, a second match is attempted -
license_number__vandlicense_degree__vandtype_value__vandlast_name__v. - If a match is not found, a third match is attempted -
license_number__vandlicense_degree__vandtype_value__v.
- If a match is not found, a second match is attempted -
Local record
-
License owner: Local -
license_number__vandlicense_degree__vandtype_value__vandfirst_name__vandlast_name__v.- If a match is not found, a second match is attempted -
license_number__vandlicense_degree__vandtype_value__vandlast_name__v. - If a match is not found, a third match is attempted -
license_number__vandlicense_degree__vandtype_value__v.
- If a match is not found, a second match is attempted -
Records that do not match on these fields are added to the sln_hcp_not_found.csv file.
Records are added to the cms_hco_found.csv file if your US data matches the raw source data using the selected Year and the following fields:
Veeva record
- HCO -
vid__v
Local record
- HCO -
corporate_name__vandhco_tax_id__v
Records that do not match on these fields are added to the cms_hco_not_found.csv file.
Excluded records
HCP and HCO records are excluded from consideration for the DEA source based on the following field values:
- Licensing Authority (
type_value__v) - Must beDEA. HCP and HCO licenses that are notDEAare excluded. - License State (
record_state__v) - Is Deleted or Invalid. If the license state is Deleted or Invalid, HCP and HCO licenses are excluded.
Match criteria
For the records that are included in the job, your US data is matched to the raw source data using the following fields based on license owner:
Veeva records (HCPs and HCOs)
- License owner: Veeva -
vid__vandlicense_number__v - License owner: Local -
license_number__v
Local record (HCPs and HCOs)
- License owner: Local -
license_number__v
Records that do not match on these fields are added to the dea_<entity>_not_found.csv file.
Records that match on the selected Year and the following fields are added to the ma_cri_hcp_found.csv file:
Veeva records
- HCP -
vid__v
Local record
- HCP -
cri_id__vandlast_name__v
Records that do not match on these fields are added to the ma_cri_hcp_not_found.csv file.