Match
Add request match rules
The default match rules used by add requests and change requests are improved to reduce the potential for over matching.
This enhancement is enabled by default in your Network instance.
Countries
Changes will be made to the following countries:
-
EMEA region
-
United States
View default match rules
All countries supported by Veeva OpenData have default match rules for add and change requests.
To view the match rules:
-
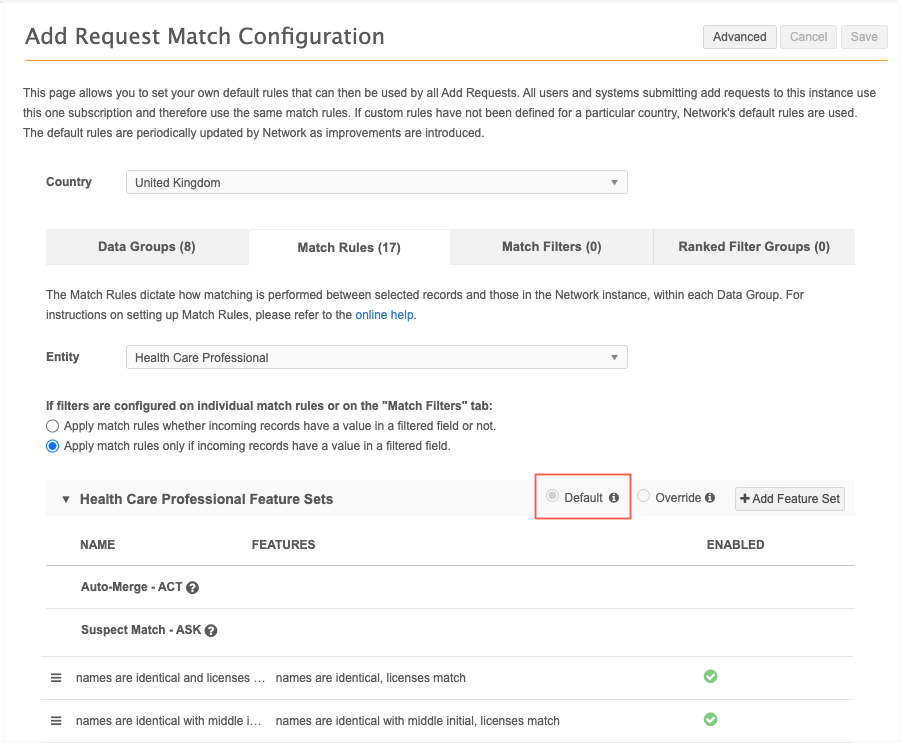
In the Admin console, click System Interfaces > Add Request Match Configuration.
-
Choose a country.
Data groups, match rules, and filters display for the country and selected entity.
-
If the Default is selected, the entity uses the default match rules. If Override is selected, the rules have been customized.
Custom match rules
If you have made changes to the default match rules, these updates will not impact your custom rules.