Veeva OpenData AMA subscription
DM
As of January 1, 2022, US Veeva OpenData subscriptions no longer include American Medical Association (AMA) data. Fields previously provided by the AMA have been grouped together to form an AMA data subscription. For Network MDM customers that had a subscription to US OpenData prior to 2022, the behavior of the fields depending on your agreement with the AMA.
If you subscribed to US OpenData since January 1, 2022, the AMA data subscription is inactive and can be ignored.
Active subscription behavior
If the Include AMA data subscription is enabled in your Network MDM instance, those fields will always be empty. They are managed by OpenData but the US OpenData team will never load data into any of then.
You can disable the AMA fields in your Network MDM instance. When the fields are disabled, they no longer display on record profiles and cannot be included in data change requests.
Inactive subscription behavior
If the Include AMA data subscription is inactivated in your Network MDM instance, the fields are locally managed.
The following behavior occurs to the Veeva managed AMA fields and data when the subscription is inactive:
-
The AMA fields are locally managed. You own and manage the fields including any data that might exist therein.
-
If data change requests are submitted on inactive AMA fields, the changes will be sent to your local data stewards.
Note: If the subscription is inactive, do not enable it. AMA data is no longer included in US OpenData subscriptions.
AMA data considerations for OpenData records
-
The AMA fields remain on Veeva OpenData records, but they are locally managed. You will need to load AMA data from another data provider if you want current data in those fields on OpenData records.
Fields included in the subscription
The following HCP fields are exclusive to AMA data and are no longer managed by OpenData.
The fields can be inactivated if the AMA subscription is not selected.
| HCP Field Name | Localized UI Label | Field Type | |
|---|---|---|---|
| 1 |
alternate_first_name__v |
Alternate First Name | String |
| 2 | alternate_last_name__v | Alternate Last Name | String |
| 3 | alternate_middle_name__v | Alternate Middle Name | String |
| 4 | ama_do_not_contact__v | AMA Do Not Contact? | Reference |
| 5 | birth_country__v | Birth Country | Reference |
| 6 | education_level__v | Education Level | Reference |
| 7 | fellow__v | Fellow | Reference |
| 8 | grad_school__v | Graduation School | String |
| 9 | grad_training__v | Grad Training? | Reference |
| 10 | grad_trg_end_date__v | Grad Training End Date | Date |
| 11 | grad_trg_start_date__v | Grad Training Start Date | Date |
| 12 | me_id__v | ME ID | String |
| 13 | mpa__v | Major Professional Activity | Reference |
| 14 | pdrp_optout__v | PDRP Opt Out? | Reference |
| 15 | pdrp_optout_date__v | PDRP Opt Out Date | Reference |
| 16 | place_of_employment__v | Place of Employment | Reference |
| 17 | type_of_practice__v | Type of Practice | Reference |
| 18 | years_in_progress__v | Years in Progress | Number |
Loading AMA data from other data sources
If you receive AMA data from a third party data provider, you can load the data into Network MDM through a source subscription.
Options for loading AMA data:
-
Existing subscription - Augment an existing subscription to use fields that already exist on the files from that source.
Source subscriptions that already add data from that source to OpenData records into custom fields should not require updates to match rules but this should be reviewed to ensure that updates and new data is added.
-
Clone a subscription - Make a copy of an existing subscription that uses this source. This enables you to leverage some of the subscription configuration and just add new files and fields.
-
New subscription - Create a new subscription to load this data from files provided by your new AMA data provider.
Note: If you receive raw AMA fields from a data licensee (DBL), data transformation work is required to create files that can be loaded into Network MDM. Then, use a new subscription to load the data into the locally managed fields. See the “Transforming raw AMA data files” section below.
Configure a source subscription
Create the subscription configuration so you can load your new data files.
- In the Admin console, click System Interfaces > Source Subscriptions.
-
Click Add Subscription > Use Wizard Mode.
When you use the wizard, you add a sample file for your data. The file can have no more than 50 rows.
-
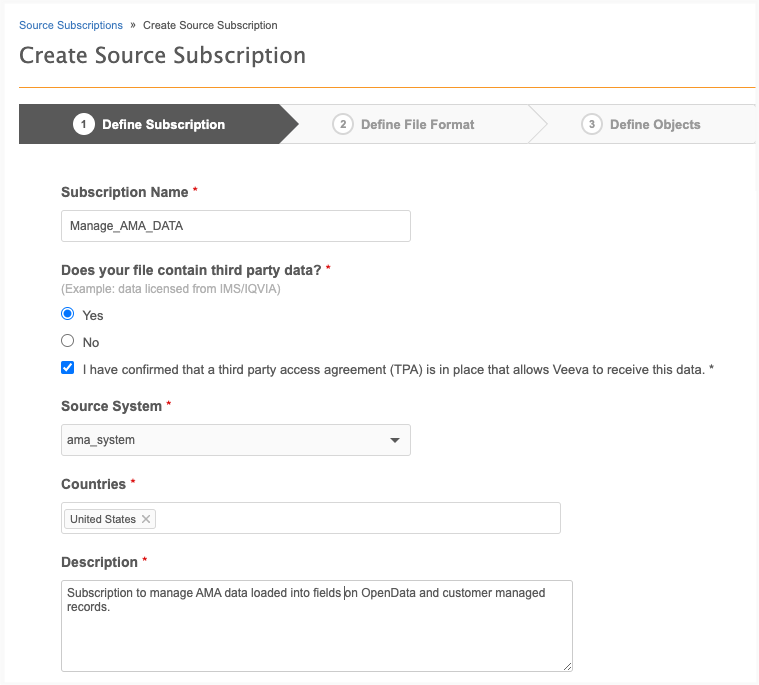
On Step 1 - Define Subscription, provide the following details:
-
Subscription name - Type a meaningful name for this subscription.
-
Third party data - Confirm that the file does contain third party data and that you have an agreement. You must have an agreement with the AMA to load the data to Network MDM.
-
Source system - Choose the system that you have created for the data source.
If you haven't yet created a system, go to System Interfaces > Systems to add the data source.
-
Countries - Add United States as the country. AMA data applies only to the United States.
-
Description - Type a meaningful description for this subscription.
-
Upload Sample Files - Add the AMA data file to the subscription. The file will be validated. If there are any warnings or errors, fix them and upload the file again.
Click Save & Continue.
-
- On Step 2 - Define File Format, define the following settings:
Filename prefix on the FTP server - The prefix of the file that you will regularly use for this subscription. For example, the file name might change to indicate a date but the beginning of the file name will always be the same.
The field is automatically populated with the prefix of the file that you loaded. Edit the prefix if this is not correct for future files.
File Format - Indicate how the fields in the file are separated. Choose Fixed Length or Delimited. Delimited is selected by default.
If you choose Fixed Length, type the allowed character lengths for each column into the Fixed Length Widths field.
- If you choose Delimited, Network MDM tries to identify how the file is formatted. Ensure that the following settings are correct:
- Delimiter - Identify how the data in the file is separated.
- File Text Qualifier - The characters that identify separate fields.
Note: If you uploaded an .xlsx file, these fields do not display. Network MDM automatically identifies the format.
Headers - Confirm that your file includes headers. Your file should use the Network MDM field names as column headers.
A preview of the file displays in the format that you identified.
Click Save & Continue.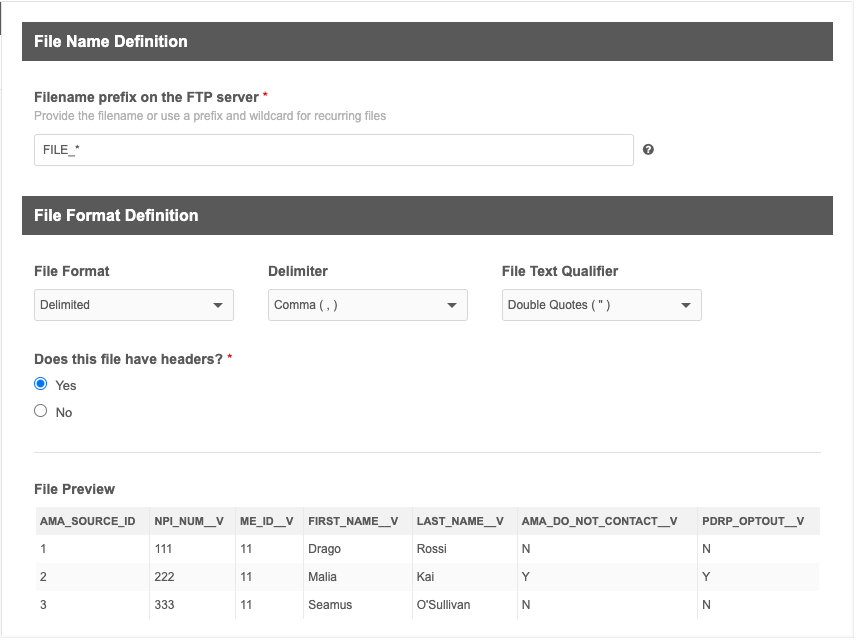
-
On Step 3 - Define objects, expand the list and choose Health Care Professional (HCP).
There are no other objects in the file, so there is no need to define criteria for loading records.
Click Save & Continue.
-
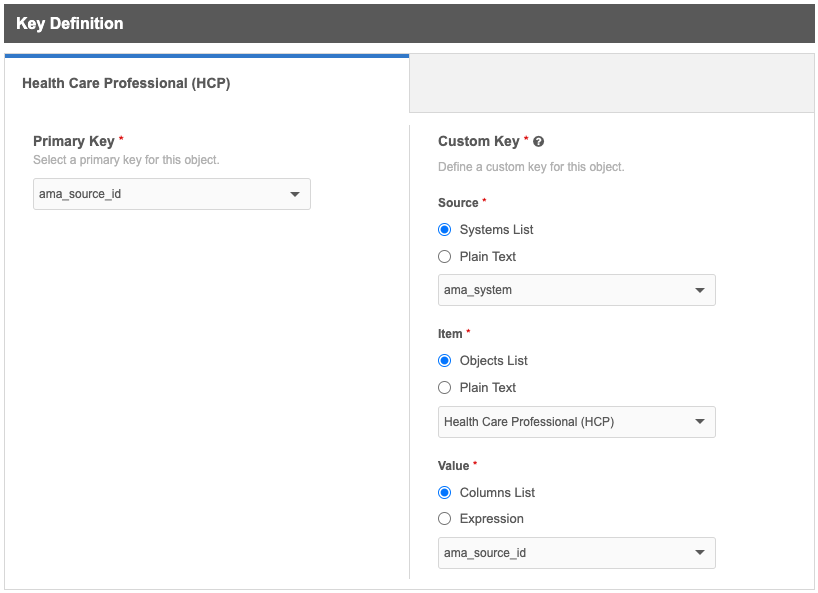
On Step 4 - Select Keys, identify the primary key and configure the custom key for the HCP object.
-
Primary key - Choose the field that will be the primary key for the HCP. For example, ama_source_id.
-
Custom Key - Custom keys are based on the system name, object, and external ID; for example, ama_system:HCP:0540417133.
-
Source - The source system for this subscription. The system that you selected for this subscription is the default value. You can choose any system that is defined in your Network MDM instance or choose Plain Text to type a source; for example, AMA.
-
Item - A value distinguishes this key from other keys. Objects are typically used for the Item value. You can also click Plain Text and type a unique value.
-
Value - Typically, the custom key value is an external ID. Expand the Columns List to choose any of the columns in this file. Alternately, select Expression to use a Network Expression to create the value. The syntax is not validated here but is validated when the subscription runs.
Click Save & Continue.
-
-
-
On Step 5 - Map Fields, map the fields from your source file to Network MDM fields.
In some cases, fields in your file are automatically mapped:
- If the field names in your file match Network MDM fields exactly, the Network MDM fields are automatically populated.
- Network MDM identifies the fields that you have selected as the primary key. A Primary Key icon displays beside the field so you know that it does not need to be mapped.
- Click Generate Subscription. The subscription opens in Classic Mode so you can review the model map and field normalization, define match rules, and make any other changes.
-
Consider the following for the Match Configuration section:
-
Key Matching - If you are using data from an existing source and they’ve provided keys that match keys that you have already loaded into Network MDM for HCPs by that source, this incoming data will match using those keys automatically. The default match rules are not required.
-
Match on NPI - US default match rules already match on the NPI number.
As long as your incoming data has an NPI value, you can use that for matching purposes for new records.
-
Match on ME ID - You can also match on ME ID but that will only maintain records that already have AMA data loaded, including ME ID.
Since ME ID is one of the data elements that you need to maintain yourself, you need to find another element (custom key, NPI) to match with. Once a match is found, a new or updated ME ID can then be associated to records.
-
- Add the source files to the FTP server so the subscription can retrieve them when it runs.
Transforming raw AMA data files
If you receive raw data files, they must be transformed before they can be loaded into Network MDM. After you develop the transformation, it can be used each time you receive updated files.
Supported data files
There are many raw AMA data files; this information focuses on content in the weekly PPD delta file only. AMA provides two versions of this weekly file: a before file and an after file.
This information only covers updating or adding data to OpenData or locally managed records for the 18 fields that will be transformed from the PPD file.
Note: You can use all of the 18 HCP fields or you can choose to use fewer fields.
Not covered in this document
This information does not cover the following files from AMA:
-
Student file - Adding and updating student records.
-
Dead file - Updates for HCPs who are deceased.
-
Quarterly file - A file that AMA provides each quarter that contains all updates.
Transforming the PPD file data
The raw data in the PPD file must be transformed before it can be loaded into Network MDM. This is a process that customers will develop internally. Once the transform has been created, it can be used weekly each time you receive the PPD delta file.
When you build the transformation, it should include the following elements:
-
File headers - The AMA PPD file does not contain headers. The following headers are based on the file layout provided by the AMA.
Use the following headers so the columns can be mapped to columns with Network MDM data model names.
ME_NUMBER|RECORD_ID|UPDATE_TYPE|ADDRESS_TYPE|MAILING_NAME|LAST_NAME|FIRST_NAME|MIDDLE_NAME|SUFFIX|MAILING_LINE_1|MAILING_LINE_2|CITY|STATE|ZIP|SECTOR|CARRIER_ROUTE|ADDRESS_UNDELIVERABLE_FLAG|FIPS_COUNTY|FIPS_STATE|11_DIGIT_ZIP_CODE_PRINT_CTRL_CODE_1|11_DIGIT_ZIP_CODE_ZIP|11_DIGIT_ZIP_CODE_SECTOR|11_DIGIT_ZIP_CODE_DELIV_POINT_CODE|11_DIGIT_ZIP_CODE_CHECK_DIGIT|11_DIGIT_ZIP_CODE_PRINT_CTRL_CODE_2|CENSUS_REGION|CENSUS_DIVISION|CENSUS_GROUP|CENSUS_TRACT|CENSUS_SUFFIX|CENSUS_BLOCK_GROUP|CENSUS_MSA_POPULATION_SIZE|CENSUS_METROPOLITAN_MICROPOLITAN_INDICATOR|CENSUS_CBSA|CENSUS_CBSA_DIVISION_INDICATOR|CENSUS_DEGREE_TYPE|BIRTH_YEAR|BIRTH_CITY|BIRTH_STATE|BIRTH_COUNTRY|GENDER_CODE|TELEPHONE_NUMBER|PRESUMED_DEAD_FLAG|FAX_NUMBER|PRIM_TOP|PRIM_PE|PRIM_AMA_SELF_DESIGNATED_PRACTICE_SPEC|SEC_AMA_SELF_DESIGNATED_PRACTICE_SPEC|MAJ_PROF_ACTIVITY_PRIM|PRA_RECIPIENT|EXPIRATION_DATE|CONFIRMATION_FLAG|FROM_DATE|TO_DATE|YEAR_IN_PROGRAM|POST_GRAD_YEAR|SPECIALTY_TRAINING_1|SPECIALTY_TRAINING_2|SPECIALTY_TRAINING_TYPE|INSTITUTION_STATE|INSTITUTION_ID|GRAD_MEDICAL_SCHOOL_STATE|GRAD_MEDICAL_SCHOOL_ID|GRAD_MEDICAL_SCHOOL_STATE_YR_GRAD|CONTACT_INDICATOR|NO_WEB_FLAG|RX_RESTRICTION_IND|RX_RESTRICTION_START_DATE|OFFICE_MAILING_LINE_1|OFFICE_MAILING_LINE_2|OFFICE_MAILING_LINE_3_CITY|OFFICE_MAILING_LINE_3_STATE|OFFICE_MAILING_LINE_3_ZIP|OFFICE_MAILING_LINE_3_SECTOR|CARRIER_ROUTE_CODE|MOST_RECENT_FORMER_LAST_NAME|MOST_RECENT_FORMER_MIDDLE_NAME|MOST_RECENT_FORMER_FIRST_NAME|NEXT_MOST_RECENT_FORMER_LAST_NAME|NEXT_MOST_RECENT_FORMER_MIDDLE_NAME|NEXT_MOST_RECENT_FORMER_FIRST_NAME
-
Field mapping - Map the AMA field names to the 18 Network MDM field names.
Only these 18 fields are required for updating the AMA data in Network MDM. You can use all 18 fields or use a fewer number of fields.
When this field mapping is done as part of the transformation, no additional field mapping is required (for example, no mapping is required in the source subscription).
AMA Raw File Field Name Network MDM Field Name 1 MOST_RECENT_FORMER_FIRST_NAME alternate_first_name__v 2 MOST_RECENT_FORMER_LAST_NAME alternate_last_name__v 3 MOST_RECENT_FORMER_MIDDLE_NAME alternate_middle_name__v 4 CONTACT_INDICATOR ama_do_not_contact__v 5 BIRTH_COUNTRY birth_country__v 6 This is a calculated field based on INSTITUTION_ID and internal logic education_level__v 7 SPECIALTY_TRAINING_TYPE fellow__v 8 GRAD_MEDICAL_SCHOOL_STATE+GRAD_MEDICAL_SCHOOL_ID grad_school__v 9 CONFIRMATION_FLAG grad_training__v 10 TO_DATE grad_trg_end_date__v 11 FROM_DATE grad_trg_start_date__v 12 ME_NUMBER me_id__v 13 MAJ_PROF_ACTIVITY_PRIM mpa__v 14 RX_RESTRICTION_IND pdrp_optout__v 15 RX_RESTRICTION_START_DATE pdrp_optout_date__v 16 PRIM_PE place_of_employment__v 17 PRIM_TOP type_of_practice__v 18 YEAR_IN_PROGRAM years_in_progress__v -
File - Create a file called HCP.csv. This file will contain only the 18 fields for the transformed data. It is the only file to use in the source subscription to load this data.
Field/Column considerations
Changes are required for some of the fields during the transform.
-
ME_NUMBER (me_id__v) - The ME_NUMBER provided by the AMA is 11 characters. The first 10 characters are the true ME_NUMBER and the 11th character is a check number.
-
UPDATE_TYPE - This column is used for the AMA Weekly Delta PPD file to indicate versions of the record. There are two versions of the delta file sent weekly; a before version and an after version.
-
When UPDATE_TYPE = 1, then the record is the previous version of the data.
-
When UPDATE_TYPE <> 1, then the record is the new version of the data and should be loaded.
-
-
CONTACT_INDICATOR (ama_do_not_contact__v) - This field can contain the following values: Y, N.
The values have opposite meanings between the AMA field and the Network MDM field because of the name of the fields.
CONTACT_INDICATOR
AMA PPD FieldAMA DO NOT CONTACT?
Network MDM FieldY (Contact is allowed) N (Contact is allowed) N (Contact is not allowed) Y (Contact is not allowed) - RX_RESTRICTION_IND (pdrp_opt_out__v) - This field can contain the following values: Y, N.
The values have the same meaning between the AMA field and the Network MDM field: Y = Y and N =N.
-
CONFIRMATION_FLAG (grad_training__v) - This field can contain the following values: Y, N.
CONFIRMATION_FLAG
AMA PPD FieldGRAD TRAINING?
Network MDM Field(blank value) N Y Y -
PRIM_TOP (type_of_practice__v) - This is a lookup field.
The AMA values map to the following Network MDM reference codes:
AMA Value Network MDM Code English Description 012 20 Resident 020 4 Direct Patient Care 030 40 Administration 040 1 Medical Teaching 050 21 Medical Research 062 50 Non-Patient Care 070 90 Inactive 071 98 Retired 072 97 Semi-Retired 073 96 Disabled 074 95 Temporarily Not In Practice 075 90 Inactive 100 99 Not Classified - MAJ_PROF_ACTIVITY_PRIM (mpa__v) - This is a lookup field.
The AMA values map to the following Network MDM reference codes:
AMA Value Network MDM Code English Description ADM 40 Administration HPP 30 Full-Time Hospital Staff HPR 20 Resident INA 90 Inactive LOC 5 Locum Tenens MTC 1 Medical Teaching NCL 99 Not Classified OFF 4 Office Based Practice OTH 80 Other RES 21 Research SRT 89 Semi-Retired -
PRIM_PE (place_of_employment__v) - This is a lookup field.
The AMA values map to the following Network MDM reference codes:
AMA Value Network MDM Code English Description 011 2 Self-Employed Solo Practice 013 6 Group Practice 014 6 Group Practice 021 4 Other-Patient Care 022 5 Locum Tenens 030 6 Group Practice 035 7 HMO 040 1 Medical School 050 30 Non-Government Hospital 060 99 Not Classified 063 31 City/Country/State Government Hospital 064 32 City/Country/State Other Than Hospital 080 99 Not Classified 081 33 Federal Government-Hospital Army 082 34 Federal Government-Hospital Navy 083 35 Federal Government-Hospital Air Force 084 36 Federal Government-Hospital USPHS 085 37 Veteran Affairs 086 38 Other Federal Agency 101 50 Other-Non-Patient Care 110 99 Not Classified
Data loading considerations
There are other considerations after transforming the AMA data and producing an HCP file. Additional work might be required to load the data into Network MDM.
Matching data to existing records
The HCP.csv file will contain only the 18 fields. Network MDM's default match rules will match on the ME ID field. If each row in the newly created HCP file has a value in that field, each incoming row should match using the ME ID. This will only match and update records with existing data.
Loading data to new records
Existing records can be updated by matching data. Customers must determine how to load this data into new records.
Source subscription requirements
When you create the source subscription, you'll need to specify the following:
-
Source system
-
HCP custom keys
These need to be specified when you load any data into Network MDM.
More information
If you have questions about transforming the data, contact your Veeva OpenData Customer Service Manager (CSM).