Simulating data updates
DM
Test data updates in your Production instance by running source subscription jobs in simulation mode so you can preview the outcome before committing the data to the database. This ensures that you have more control and confidence over the quality of your data operations.
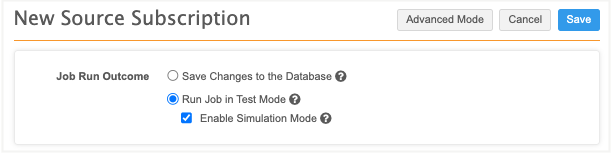
About simulation mode
When you run a job in simulation mode, the data is simulated during the merge stage. You can preview the results without committing any data to the database.
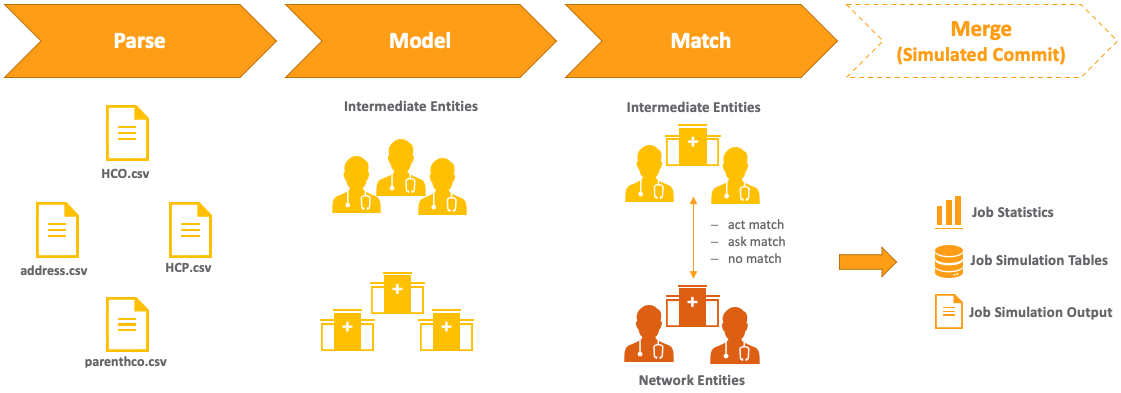
Simulated data
Examples of outcomes that you can test with simulated data:
-
Changes to critical fields - For example, address status, relationship type, HCO/HCP type, and so on.
-
Rejected records - Learn about records that will be dropped from the feed because of data issues.
Records that are rejected are not included in the simulation output, but an error displays in the Job Error Log so you can investigate the issue.
For example, if a reference code is not mapped to Network MDM, a message displays in the log so you can fix the issue. Job errors for rejected records do not display in Test Mode. -
Network expression rules - Test NEX rules in the simulated data to ensure the outcome is expected before committing it to the database.
All rule points are supported for simulation mode.
-
Network Address Inheritance - Review addresses that are synced from Parent HCOs in the output.
-
Repointing relationships
-
Bulk merging entities
Reviewing simulated data
Simulated data can be reviewed in the following areas:
-
Job statistics - Counts for added and updated records display in the Job Summary Report section on the Job Details page.
When the job is run in Test Mode, statistics are not available for the Job Summary Report. -
Files - A .zip file is created in the Network MDM file system. It contains a .csv file for each object impacted by the data. For example, if the feed contains updates for HCPs, a .csv file is created for the HCP object and for each of its sub-objects and relationships. The files for all simulation jobs are archived in the FTP folder.
-
Reporting tables - The simulation output is available as reporting tables. Use the tables to compare the simulated data with production data. Only the tables for the last run simulation job are available. Each time a simulation job starts, the previous simulation tables are replaced.
If you identify issues, you can fix them and prevent unintended data updates from being loaded into your Network MDM instance.
When the job outcome is working as expected, run the job again using the Save Changes to the Database option to commit the changes to the production database.
Running a job in simulation mode
Use the Job Run Outcome at the top of the page to define how the job will be run.
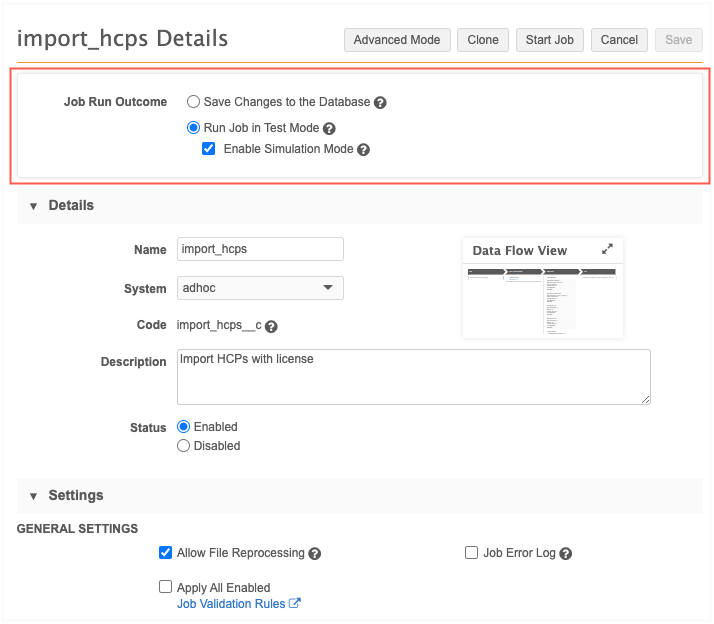
You can run a job using any of the three options:
-
Save Changes to the Database - Commit the data updates to the database.
-
Run Job in Test Mode (Default) - Stop the job after the matching stage so no changes will be applied to the database. You can review the job statistics on the Job Details page.
-
Enable Simulation Mode - Preview the changes to the production data. No changes are committed to the database.
-
Manually run a job
The Job Run Outcome options are available when you click Start Job to manually run a job.
In the Start Job confirmation dialog, the options display again in case you want to change them. 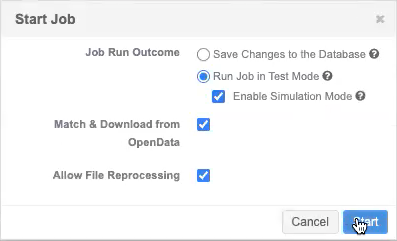
Network MDM API
If you are running the job using the API, you can use the mode parameter to specify the job outcome. The parameter value will override the configuration outcome only for the job started by the API call.
Job Details
After the job completes, review the statistics on the Job Details page and the simulated data output.
The following sections on the page are updated to support simulation mode.
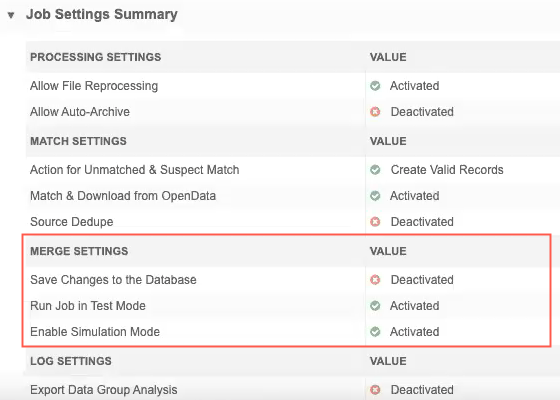
Job Settings Summary
The Merge Settings heading identifies the Job Run Outcome setting values that were applied to the job.
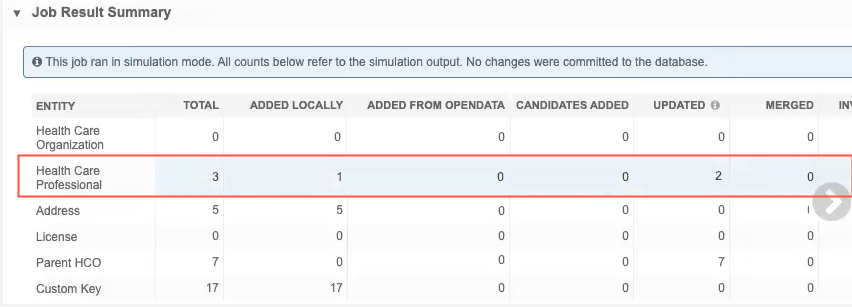
Job Result Summary
This section is populated with the simulated statistics of the job after the merge stage. A banner displays to assure you that the data is simulated and that no changes were committed to the database.
Example
In this job, if the data had been committed to the database, one HCP would have been added as a local record, and two HCPs would have been updated.
Note: When a job is set to Test Mode, it stops the job after the match stage so, job statistics display only in the Data Load Summary, Processed Data Summary, and Match Summary. The Job Result Summary section is not updated on the Job Details page.
View simulated output files
In Network Explorer, a new folder in the outbound directory, data_load_simulation, contains the output files for all simulation jobs.
Access to these files is not restricted; if you have access to the folder in the File Explorer, you can view the output files.

Each simulation job creates a .zip file with the following naming convention: <system>-<subscription_name>-data-load-simulation-<timestamp>-job<ID>.zip.
The .zip file contains a .csv file for each entity that was updated or that has new records. The complete entity is included in the output, for example, if HCPs were updated or new HCPs were added (either in the data feed or they were matched and downloaded from OpenData), all of the sub-object and relationship data is added to the simulation output.
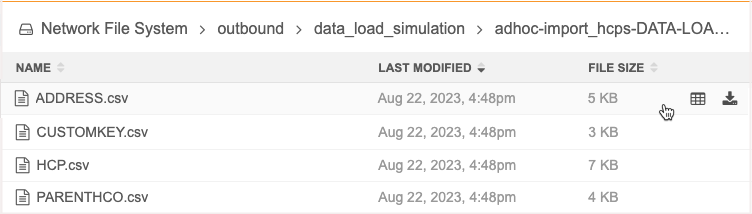
Note: If the simulation job does not create records or change any records, an empty .zip file is created.
Review the files
Reviewing the files can help you to see what might have gone wrong during the data load.
-
In the data_load_simulation directory, click the Download icon the to save the .zip file locally.
-
Extract the .csv files. A file is created for each entity that has updates or has new records. If an entity was not touched during the job, a file is not created.
-
Open a .csv file to review the simulated data.
The field values can help you to quickly identify the changes that occurred. For example, in the Address file, you can spot addresses that were inactivated or that were copied (synced) from a parent address through Network Address Inheritance.

Tip: You can also view the .csv files as Network tables![]() Files that can be opened, viewed, and augmented with data directly in Network..
Files that can be opened, viewed, and augmented with data directly in Network..
Considerations for simulated output
Records matched and downloaded from OpenData
If the Match & Download from OpenData setting was on in the source subscription configuration, records that matched will display in the simulated output.
-
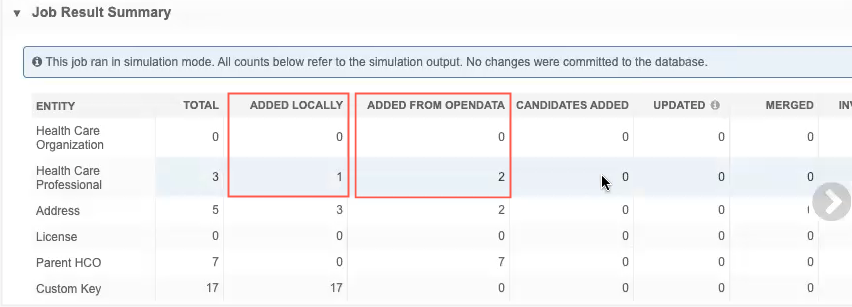
Job details - Records in the source file that are matched with OpenData records display in the Job Result Summary.
Example
if the data would have been committed to the database, one HCP record would have been created and two HCP records would have been downloaded from OpenData.
-
Simulated output files
For records that matched with OpenData records and would have been downloaded, the simulated files contain the data from OpenData as well as the data included in the source file.
Simulated alternate keys
If new records are created with an alternate key, the key counter is not incremented in simulation mode. Placeholder characters are used to reflect the key format.
Examples
In the simulated output, the alternate keys reflect the key format only; an alternate key is not generated.
-
Alpha-numeric keys: The uppercase letter X is used as a placeholder: If the alternate key format is USZJF-RQK-NKB, the simulated output displays XXXXX-XXX-XXX.
-
Numeric keys - The number 9 is used as a placeholder. If the alternate key format is 00000-0006, the simulated output displays 99999-9999
Report on simulated data
Reporting tables are created for the simulated data in the SQL Query Editor (Reports). Use the tables to generate reports so you can compare the simulated data to the production data in order to understand which changes the job would have made to your data.
If you have access to the SQL Query Editor, you can view the simulated tables and data. There are no access restrictions; for example, data visibility profiles, field restrictions, and dynamic access control do not apply.
To view the tables:
-
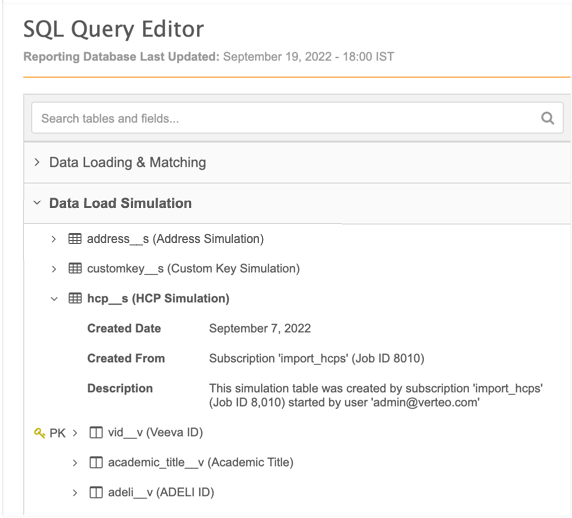
In the SQL Query Editor, expand the Data Load Simulation category. The simulated files are created as tables with the __s suffix.
Note: Only the tables from the last run simulation job display; the tables are replaced each time a simulation job is run. Reporting tables are not created if a simulation job does not create any new or changed records; the tables from the last job that produced changes are retained.
-
Expand a table to view the metadata and the fields. The metadata includes the subscription name, the job ID, and the user that created the simulation output.
Important: The tables include all data model fields for each entity so they have the same structure as production tables. This makes it easier to write the queries and compare the data.
Example queries
Create SQL queries to compare the simulated data with the production data.
Tip: Use left joins to join a simulation table with the production table because you might have new records that do not exist in the production table yet.
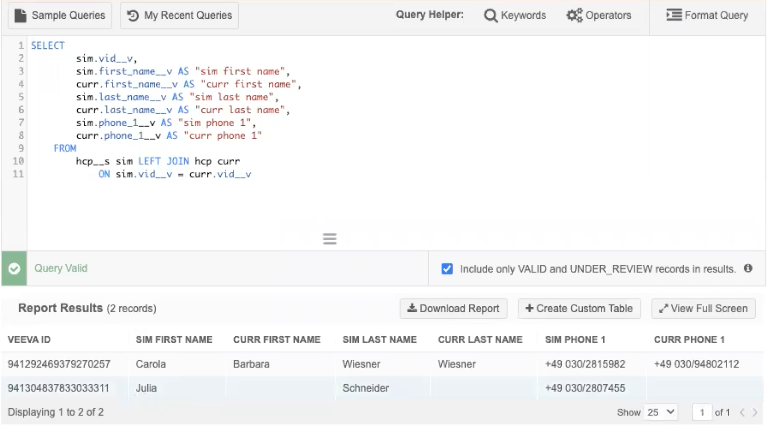
Example 1 - HCP query
This query compares specific fields between a simulated HCP table with the production data.
SELECT
sim.vid__v,
sim.first_name__v AS "sim first name",
curr.first_name__v AS "curr first name",
sim.last_name__v AS "sim last name",
curr.last_name__v AS "curr last name",
sim.phone_1__v AS "sim phone 1",
curr.phone_1__v AS "curr phone 1"
FROM
hcp__s sim LEFT JOIN hcp curr
ON sim.vid__v = curr.vid__v
Example results
In these results, you can see that the first row makes changes to an existing record and the second row creates a new record.
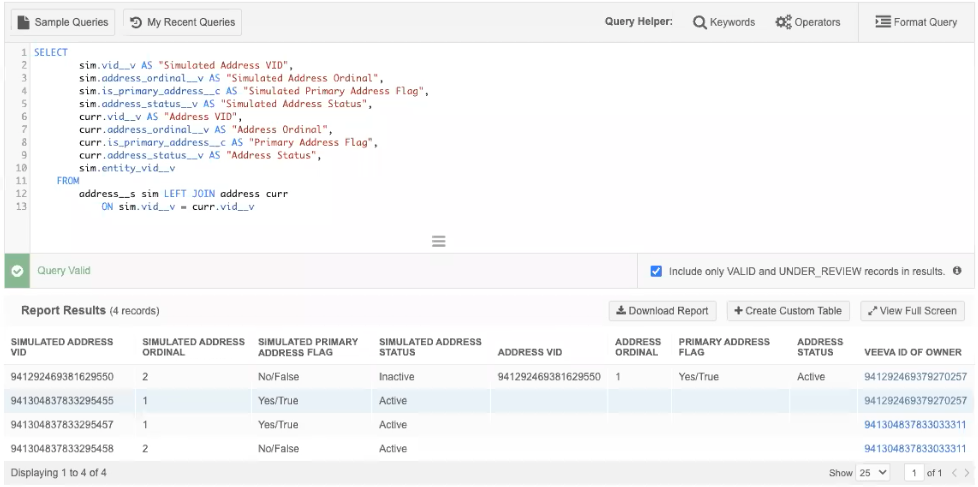
Example 2 - Address query
This query compares the data in the address simulation table to production data.
SELECT
sim.vid__v AS "Simulated Address VID",
sim.address_ordinal__v AS "Simulated Address Ordinal",
sim.is_primary_address__c AS "Simulated Primary Address Flag",
sim.address_status__v AS "Simulated Address Status",
curr.vid__v AS "Address VID",
curr.address_ordinal__v AS "Address Ordinal",
curr.is_primary_address__c AS "Primary Address Flag",
curr.address_status__v AS "Address Status",
sim.entity_vid__v
FROM
address__s sim LEFT JOIN address curr
ON sim.vid__v = curr.vid__v
Example results
The results can tell you when ordinals are recalculated because addresses are inactivated.
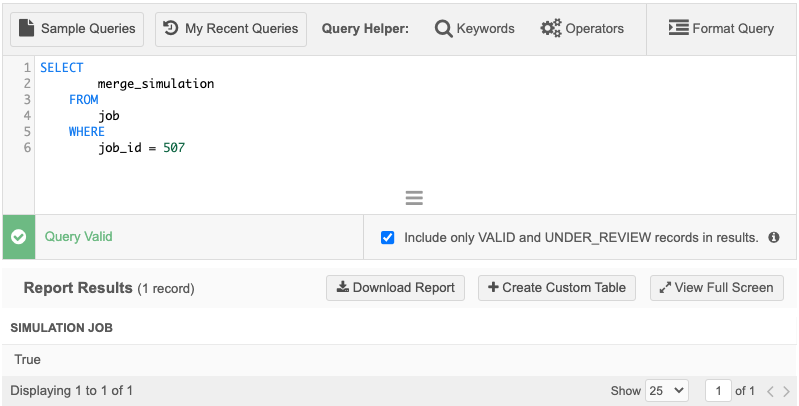
Identify jobs that ran in simulation mode
Use the merge_simulation column in the job (Job Details) table to identify source subscription jobs that ran in simulation mode.
The column value is either True or False.
Example
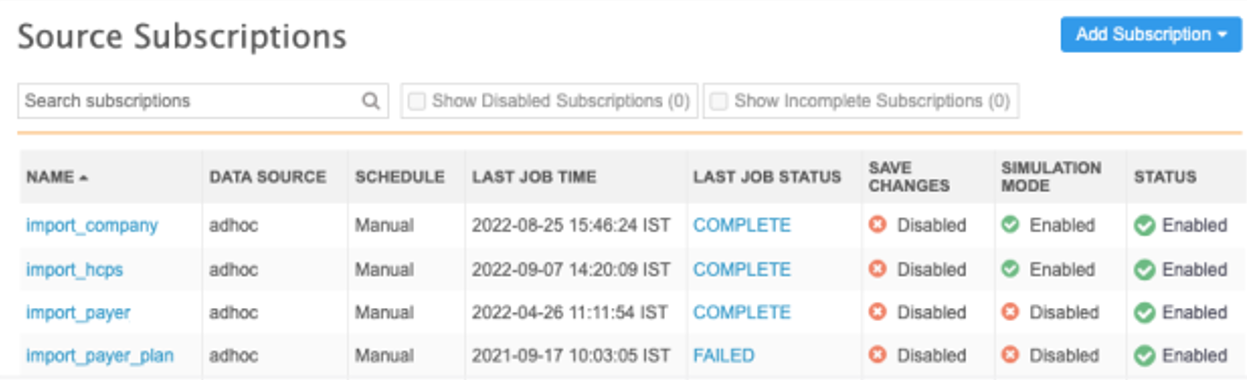
Source Subscriptions view
The Source Subscriptions page (System Interfaces) identifies the current configuration for each subscription.
Save Changes
-
 Enabled - The subscription is configured to commit changes to the database.
Enabled - The subscription is configured to commit changes to the database. -
 Disabled - The subscription is configured to run in test mode. No changes will be committed to the database.
Disabled - The subscription is configured to run in test mode. No changes will be committed to the database.
Simulation Mode
-
Enabled - The subscription is configured to simulate the job output. No changes will be committed to the database.
-
Disabled - The subscription is configured to run in test mode. No changes will be committed to the database.
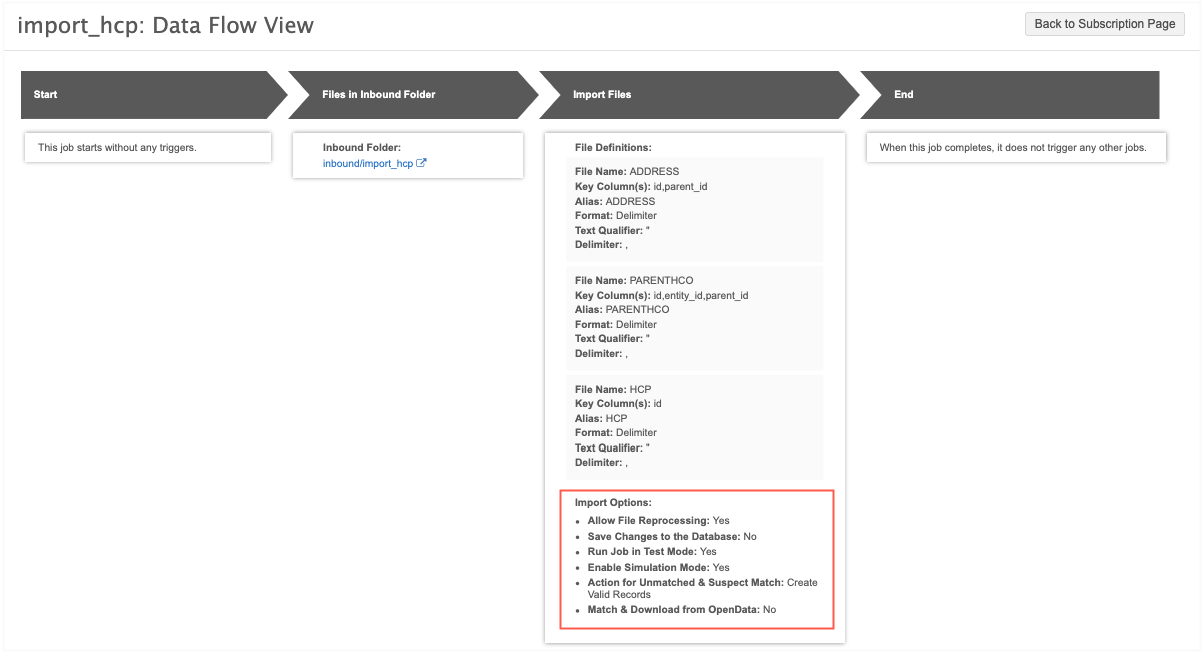
Data flow view
After a source subscription is saved, the Data Flow View displays on the configuration page.
The setting values that are applied to the current job display in the Import Files stage.
Considerations for Network IDs
When incoming records are not matched to existing records in Network MDM, new records are created for the simulated data. Network IDs that are generated for these new records are used only for the simulated output. If you run the subscription again to commit the data to the Network MDM database, new Network IDs and are generated for the records.
Job triggers
Source subscriptions that run in test mode or simulation mode cannot trigger a subsequent job to start.
The Job Run Outcome setting on the configuration must be set to Save Changes to the Database to trigger another job to start when the subscription job successfully completes.
Duplicate custom keys
If you load an entity with a custom key and that key already exists for a different entity in the production data, an error will display in the Job Error Log. You can fix the issue before you commit the data.
When different entities have the same custom key in an incoming data load, the duplicate keys cannot be detected in the simulated output. These types of duplicates can be detected, but only when the production database is updated.
Advanced properties
Some properties that are used for simulated jobs are read-only to ensure that the values do not change if they are copied and pasted between subscriptions.
The following properties are read-only:
-
job.match.skipMerge
-
job.immutable
-
job.simulation
These properties cannot be changed in Advanced Mode.
Running jobs using the API
When jobs are triggered externally using the API, use the mode parameter to control the subscription job outcome. This is helpful because you can easily toggle between the different job modes without always having to update the subscription settings.
Note: Using this parameter controls the specific job that is started by the API call; it does not change the subscription configuration.
Supported endpoints
-
api/{version}/systems/{system_name}/{subscription_type}/{subscription_name}/job
-
api/{version}/subscription/{subscription_name}/job
Possible parameter values
These values can be used for the mode parameter.
-
default - Run the subscription job using the current subscription configuration.
When one of the following parameter values are used, it overrides the configuration saved in the subscription for this job only.
-
save_changes - The changes are saved to the database.
-
test_mode - The job runs in test mode only.
-
simulation_mode - The job runs in simulation mode.
Example request
api/{version}/systems/{system_name}/{subscription_type}/{subscription_name}/job?mode=simulation_mode